RPC及消息队列的选型
最近Tim团队在进行第四期新兵训练营,讲师针对互联网系统架构常用的知识做了9堂课,这些课程的精华文章最近也在陆续发布。今天放出的是一篇介绍RPC架构的文章,通过点击原文了解这篇文章。
值得一提的是,这位讲师曾经是我们第二期新兵训练营的学员,也恭喜他在团队获得的成长。想当年Tim学习互联网开发时,并没有这么多丰富的优秀资料,只能自己在网上通过只言片语的经验独自学习。
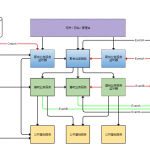
前几天在群里面也陆续讨论了RPC及消息队列的选型,部分讨论观点如下。
大家应用层的交互技术主要用什么?我这边主要是dubbo和消息队列
我之前领导是dubbo作者之一,就一直用dubbo了。。
我们自己写的rest server
各位消息队列都用啥?
Kafka和activemq
用两个消息队列。侧重点是哪些?
消息用的同阿里系 rocketmq
阿里的这些框架可以随便拿过来用吗
Dubbo rocketmq 都很成熟了
前阵子研究elk。。 flume+es, flume 参照github issue改了一点sinks和结合 es shield 的 支持加密的代码
我们是flume到kafka
你们没用uddp么?好吧。。我们自己在uddp踩了不少坑。。
现在用dubbo 有对源码做修改么?他带的依赖版本都太老了
我有小改动。灰常小 直接拿来用的话 不改也可以用。。
dubbo自带zk客户端 zkclient 比curator连接会稍慢几秒
dubbo zk client用curator,小改dubbo curatorClient代码至org.apache的curator替换老坐标的
建议服务发布,要么用xml,要么用spring boot 不要用dubbo自带annotation
不要用dubbo的@Service 。。
我们以前用也是用的xml配置
用dubbox咋样?
木有去用dubbox ,前公司做了类似dubbox的内部东西。。
我们在用dubbox,因为要和php交互
如果新项目,可以直接用spingcloud了啊
其实我挺喜欢spring httpinvoker的。。
https://softwaremill.com/mqperf/ 最新的对比,刚看完这个:When looking only at the throughput, Kafka is a clear winner
目前觉得用啥MQ都不大会成为性能瓶颈。。
kafka和dubbo一样用zookeeper啊,可以做cluster
rocketmq会有稍许 重复消息。。30W消息里有个10来条这种。。
http://nats.io/ nats 看着性能数据好NB啊。以前有一版是ruby写的,现在这版是go写的
公众号不是说zookeeper有性能瓶颈 Kafka继承了也会板着自己的脚吧
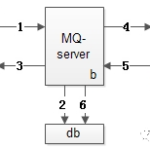
用kafka,涉及zk的有生产和消费两块,生产方面如果是php这样的程序,建议通过代理和zk.kafka交互,否则每个请求都去请求zk得到对应的kafka leader,一个是耗时高,一个是zk扛不住,通过代理的话,代理和zk,kafka长连接就好很多
消费方面,一个是也要保持类似的机制,另外一个就是楼上提到的,不要每个消费都提交offset
Load Average
在第4期日报里面介绍了一个竞赛题目,写一段代码让Linux load average最高。于是乎,黑客们八仙过海纷纷出手。当天最高的成绩可以跑到20,000左右。
昨天收到一个群友发来的最新代码,Tim不敢相信自己的眼睛,转到群里面去之后也是众说纷纭。
单机图片后可以缩放浏览。
这都不挂?我就想问一句。。。用的哪家服务器我也想用
这load,吓人,16位10进制数。这个load,机器都连不上了
这个不是机器真实负载吧,误导了机器的采集?之前运维处理过这问题
nb这个是不是修改了系统的load输入文件呀?
是fork出来就exit?
首席。。还要继续拼吗?
我得想想。。。要搞也得换语言了
透露下,方法有没有作弊。欺骗系统算法的方式算作弊。
ps的,鉴定完毕
肯定不是ps吧。如果是ps,群主颜面何在
感觉作者不是这种人,作为第一批默默写码的人
us sy 0.0
我也是看us sy那个才怀疑的
还没排除欺骗系统方式吧?
是不是修改/proc/loadaverage里面的值啊.. task数很少,top里的load值读自/proc/loadavg
应该是这么干的,再进一步就是改内核的calc_load方法,http://lxr.free-electrons.com/ident?i=CALC_LOAD
想了解产生如上load的代码如何实现?可以搜索微信公众号ArchNotes,或在文末扫码订阅高可用架构后,回复load查看答案。
想进一步同群专家进一步交流RPC选型或其他高可用架构话题,可回复arch申请进群。
点击原文可浏览上文说的微博RPC架构介绍文章