需求缘起
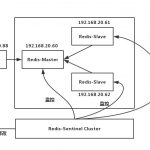
大部分互联网的业务都是“读多写少”的场景,数据库层面,读性能往往成为瓶颈。如下图:业界通常采用“一主多从,读写分离,冗余多个读库”的数据库架构来提升数据库的读性能。
这种架构的一个潜在缺点是,业务方有可能读取到并不是最新的旧数据:
(1)系统先对DB-master进行了一个写操作,写主库
(2)很短的时间内并发进行了一个读操作,读从库,此时主从同步没有完成,故读取到了一个旧数据
(3)主从同步完成
有没有办法解决或者缓解这类“由于主从延时导致读取到旧数据”的问题呢,这是本文要集中讨论的问题。
方案一(半同步复制)
不一致是因为写完成后,主从同步有一个时间差,假设是500ms,这个时间差有读请求落到从库上产生的。有没有办法做到,等主从同步完成之后,主库上的写请求再返回呢?答案是肯定的,就是大家常说的“半同步复制”semi-sync:
(1)系统先对DB-master进行了一个写操作,写主库
(2)等主从同步完成,写主库的请求才返回
(3)读从库,读到最新的数据(如果读请求先完成,写请求后完成,读取到的是“当时”最新的数据)
方案优点:利用数据库原生功能,比较简单
方案缺点:主库的写请求时延会增长,吞吐量会降低
方案二(强制读主库)
如果不使用“增加从库”的方式来增加提升系统的读性能,完全可以读写都落到主库,这样就不会出现不一致了:
方案优点:“一致性”上不需要进行系统改造
方案缺点:只能通过cache来提升系统的读性能,这里要进行系统改造
方案三(数据库中间件)
如果有了数据库中间件,所有的数据库请求都走中间件,这个主从不一致的问题可以这么解决:
(1)所有的读写都走数据库中间件,通常情况下,写请求路由到主库,读请求路由到从库
(2)记录所有路由到写库的key,在经验主从同步时间窗口内(假设是500ms),如果有读请求访问中间件,此时有可能从库还是旧数据,就把这个key上的读请求路由到主库
(3)经验主从同步时间过完后,对应key的读请求继续路由到从库
方案优点:能保证绝对一致
方案缺点:数据库中间件的成本比较高
方案四(缓存记录写key法)
既然数据库中间件的成本比较高,有没有更低成本的方案来记录某一个库的某一个key上发生了写请求呢?很容易想到使用缓存,当写请求发生的时候:
(1)将某个库上的某个key要发生写操作,记录在cache里,并设置“经验主从同步时间”的cache超时时间,例如500ms
(2)修改数据库
而读请求发生的时候:
(1)先到cache里查看,对应库的对应key有没有相关数据
(2)如果cache hit,有相关数据,说明这个key上刚发生过写操作,此时需要将请求路由到主库读最新的数据
(3)如果cache miss,说明这个key上近期没有发生过写操作,此时将请求路由到从库,继续读写分离
方案优点:相对数据库中间件,成本较低
方案缺点:为了保证“一致性”,引入了一个cache组件,并且读写数据库时都多了一步cache操作
总结
为了解决主从数据库读取旧数据的问题,常用的方案有四种:
(1)半同步复制
(2)强制读主
(3)数据库中间件
(4)缓存记录写key