深度学习的黄金时代已经到来
开场白
首先给Baidu打一波广告。Paddle深度学习平台,你值得学习。
它的优点
- 灵活性:PaddlePaddle支持广泛的神经网络结构和优化算法,很容易配置复杂的模型,如基于注意力(Attention)机制或复杂的内存(Memory)连接的神经机器翻译模型。(Attention和Memory参考阅读: 深度学习和自然语言处理中的attention和memory机制 、 深度学习:推动NLP领域发展的新引擎 )
- 高效:在PaddlePaddle的不同层面进行优化,以发挥异构计算资源的效率,包括计算、内存、架构和通信等。例如:
- 通过SSE/AVX内部函数,BLAS库(例如MKL,ATLAS,CUBLAS)或定制CPU/GPU内核优化的数学运算。
- 高度优化循环网络,以处理可变长度序列,无需填充(Padding)。
- 优化高维稀疏数据模型的本地和分布式训练。
- 可扩展性:PaddlePaddle很容易使用多个CPU/GPU和机器来加快你的训练,通过优化通信实现高吞吐量、高性能。
- 连接产品:PaddlePaddle易于部署。在百度,PaddlePaddle已经被部署到广大用户使用的产品或服务,包括广告点击率(CTR)的预测,大型图像分类,光学字符识别(OCR),搜索排名,计算机病毒检测,推荐等。
来自网络
初识
先做一个形象的比喻,Paddle就好比一台3D打印机,我们设计的神经网络就好比需要打印的模型,而我们的数据集就相当于原材料,把两者同时提供给这台打印机,经过一段时间就可以得到我们预期的产品--模型(Trained Model).
简言之,paddle 做的工作就是利用我们设计的模型和我们提供的数据 通过高性能的并行技术(CPU/GPU)来完成训练。
所以,我们在使用 Paddle 做深度学习时最基本的工作就是设计一个完美的模型并准备好数据。也就是要有以下几个文件:

- trainer_config.py : 配置神经网络模型
- data_provider.py : 数据提供
- train.sh : 配置paddle训练的参数
安装
paddle提供了三种安装方式:
- Docker 安装,非常便捷,但必须在Docker环境下部署。
- deb 安装, 在Ubuntu下打包安装。
- 编译安装 文档上写的有点复杂,其实很简单,先处理完一些依赖库,比如
MKL/BLAS、protobuf以及CUDA之类的(非GPU用户不用担心)。然后就是最基本的操作 make 之类了。每个用户都可以去尝试一下,可拓展性和可操作性都很强。
简单使用
1. 数据
可以分为如下两步:
- 定义数据格式
- 通过生成器和
yield方式提供数据
以手写字
MNIST作为例子
数据样例:
5;0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0.215686 0.533333 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0.67451 0.992157 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0.070588 0.886275 0.992157 0 0 0 0 0 0 0 0 0 0 0.192157 0.070588 0 0 0 0 0 0 0 0 0 0 0 0 0 0.670588 0.992157 0.992157 0 0 0 0 0 0 0 0 0 0.117647 0.933333 0.858824 0.313725 0 0 0 0 0 0 0 0 0 0 0 0.090196 0.858824 0.992157 0.831373 0 0 0 0 0 0 0 0 0 0.141176 0.992157 0.992157 0.611765 0.054902 0 0 0 0 0 0 0 0 0 0 0.258824 0.992157 0.992157 0.529412 0 0 0 0 0 0 0 0 0 0.368627 0.992157 0.992157 0.419608 0.003922 0 0 0 0 0 0 0 0 0 0.094118 0.835294 0.992157 0.992157 0.517647 0 0 0 0 0 0 0 0 0 0.603922 0.992157 0.992157 0.992157 0.603922 0.545098 0.043137 0 0 0 0 0 0 0 0.447059 0.992157 0.992157 0.956863 0.062745 0 0 0 0 0 0 0 0 0.011765 0.666667 0.992157 0.992157 0.992157 0.992157 0.992157 0.745098 0.137255 0 0 0 0 0 0.152941 0.866667 0.992157 0.992157 0.521569 0 0 0 0 0 0 0 0 0 0.070588 0.992157 0.992157 0.992157 0.803922 0.352941 0.745098 0.992157 0.945098 0.317647 0 0 0 0 0.580392 0.992157 0.992157 0.764706 0.043137 0 0 0 0 0 0 0 0 0 0.070588 0.992157 0.992157 0.776471 0.043137 0 0.007843 0.27451 0.882353 0.941176 0.176471 0 0 0.180392 0.898039 0.992157 0.992157 0.313725 0 0 0 0 0 0 0 0 0 0 0.070588 0.992157 0.992157 0.713725 0 0 0 0 0.627451 0.992157 0.729412 0.062745 0 0.509804 0.992157 0.992157 0.776471 0.035294 0 0 0 0 0 0 0 0 0 0 0.494118 0.992157 0.992157 0.968627 0.168627 0 0 0 0.423529 0.992157 0.992157 0.364706 0 0.717647 0.992157 0.992157 0.317647 0 0 0 0 0 0 0 0 0 0 0 0.533333 0.992157 0.984314 0.945098 0.603922 0 0 0 0.003922 0.466667 0.992157 0.988235 0.976471 0.992157 0.992157 0.788235 0.007843 0 0 0 0 0 0 0 0 0 0 0 0.686275 0.882353 0.364706 0 0 0 0 0 0 0.098039 0.588235 0.992157 0.992157 0.992157 0.980392 0.305882 0 0 0 0 0 0 0 0 0 0 0 0 0.101961 0.67451 0.321569 0 0 0 0 0 0 0 0.105882 0.733333 0.976471 0.811765 0.713725 0 0 0 0 0 0 0 0 0 0 0 0 0 0.65098 0.992157 0.321569 0 0 0 0 0 0 0 0 0 0.25098 0.007843 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0.94902 0.219608 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0.968627 0.764706 0.152941 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0.498039 0.25098 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0;数据可拆分为 label 和 784 的一个浮点数一维向量。
定义数据格式
在 data_provider.py中,有两种方式定义输入数据格式
1. 通过装饰器直接定义
@provider(input_types=[dense_vector(784), integer_value(10)],cache=CacheType.CACHE_PASS_IN_MEM)定义了一个稠密的784维向量和一个范围从0~10的整数。
或者可以有如下定义
@provider(input_types={
'pixel': dense_vector(784),
'label': integer_value(10)
},cache=CacheType.CACHE_PASS_IN_MEM
)这样通过字典定义,可以方便标记和访问。
2. 通过init_hook间接定义
def initialize(settings, **kwargs):
s = dict()
s['data'] = dense_vector(784)
s['label'] = integer_value(10)
settings.input_types = s
@provider(init_hook=initialize,cache=CacheType.CACHE_PASS_IN_MEM)通过init_hook方式更加灵活,可以动态修改输入的数据类型。另外,在init_hook方法中可以提前对settings进行配置或者动态添加一些参数,供后续工作使用。
关于两种方式的选择依据个人需求。
通过生成器和yield提供数据
yield方用法 具体查看Python文档
定义好数据格式后,就可以开始结合那个@provider装饰器提供数据了。
@provider(input_types=[dense_vector(784), integer_value(10)],cache=CacheType.CACHE_PASS_IN_MEM)
def process(settings, filename):
with open(filename, 'r') as f:
for line in f:
label, pixel = line.split(';')
pixels_str = pixel.split(' ')
pixels_float = []
for each_pixel_str in pixels_str:
pixels_float.append(float(each_pixel_str))
yield {"pixel": pixels_float, 'label': int(label)}下面来介绍一下这个函数的一些内容:
settings:这是一个全局的配置。里面可以访问一些变量,尤其是我们在init_hook中动态添加的属性。filename:显然,我们获取数据需要文件。这个file就是我们需要准备的训练集和测试文件。然而我们并不会主动去调用函数,一切调用交给了Paddle。那么我们怎么把数据提交给Paddle,Paddle又如何把数据以filename的方式交给上述的data_provider中的process处理呢?
下面要引入另外几个特殊的文件
- train.list 一个简单的文本文件,将训练文件的目录写进去,比如
data/mnist.txt - test.list 存放测试文件,内容同上。
这些文件处理好后,直接交给paddle,然后我们就可以在data_provider中对我们写进这两个文件里的训练文件和测试文件(data/mnist.txt) 进行读取操作了。

如上图:整个数据提供的顺序为:
- 将
test.list和train.list提供给 Paddle - Paddle 将
test.list和test.list中的数据文件(如MNIST.txt) 传给data_provider.py data_provider.py将数据分离成对应的input_types传递给PaddlePaddle将 数据向量 和trainer_config.py中的模型结合起来训练并测试模型。
补充
input_types:- dense_vector 表示稠密的浮点数向量.
- sparse_binary_vector 表示稀疏的零一向量,即大部分值为0,有值的位置只能取1.
- sparse_vector 表示稀疏的向量,即大部分值为0,有值的部分可以是任何浮点数.
- integer_value 表示整数标签。
cache:- NO_CACHE :不缓存任何数据,每次都会从python端读取数据
- CACHE_PASS_IN_MEM :第一个pass会从python端读取数据,剩下的pass会直接从内存里 读取数据。
2. 模型配置
还是以手写字为例
在 trainer_config.py 中 开始配置模型, 模型配置分三部分
- 数据提供
- 算法配置
- 网络配置
首先
from paddle.trainer_config_helpers import *数据提供
define_py_data_sources2(
train_list='train.list',
test_list='test.list',
module='data_provider',
obj=process,
args={
//
}
)这个函数可以向paddle配置数据输入。
module: Data Provider 的脚本文件名如data_provider对应data_provider.pyobj:对应数据提供函数(含有yield)args:为可选项,可以提供一些键值数据给init_hook函数作为函数调用的自定义参数。
算法配置
settings(
batch_size=batch_size,
learning_rate=0.001,
learning_method=RMSPropOptimizer(),
regularization=L2Regularization(8e-4)
)这个用于配置深度神经网路的一些参数, 比如学习率,batch_size,以及正则化方法和学习方法。后面会对这些参数做详细的分析。
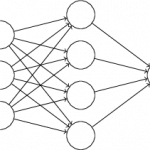
网络配置
- 输入数据获取
data = data_layer(name='data', size=784)
label = data_layer(name='label', size=10)- 神经网络配置
最基本网络模型 -- Fully Connected Layer 全连接层
# 第一个全连接隐层 有 64 个神经元 激活函数为 Sigmoid 函数
full_layer = fc_layer(input=data, size=64, act=SigmoidActivation())
# 第二个全连接隐层 有 32 个神经元 激活函数为 ReLU 函数
full_2_layer = fc_layer(input=full_layer, size=32, act=ReluActivation())
# 输出层 有10个神经元, 激活函数为Softmax
output_layer = fc_layer(input=full_2_layer, size=10, act=SoftmaxActivation())
# 计算分类损失,并执行误差反向传播
cost = classfication_cost(input=output_layer, label=label)
# 输出
output(cost)output 一般作为模型配置的结束点,没有output会导致paddle报异常的错误。
神经网络Layer还有很多种类,如 LSTM,CNN,RNN以及各种pool。会在以后的介绍中提到。
3. 训练
run shell scripts
cfg=trainer_config.py
paddle train \
--config=$cfg \ # 模型配置
--save_dir=$output_dir \ # 输出文件存储目录
--trainer_count=64 \ # GPU个数或者CPU个数
--log_period=1000 \ #
--dot_period=100 \ # 每一个period的输出dot的数量
--num_passes=50 \ # 训练轮数
--use_gpu=false \ # 是否使用GPU
--show_parameter_stats_period=3000 \run后paddle就会开始训练,深度学习的大门就开启了。
总结
Paddle 刚开源不久,确实存在一些问题,Baidu开发者也在不断更新完善(回复issue的速度贼快)。但熟悉后会觉得这个框架可用性很强。支持国产!
关于作者
- 本科生 大二
- email: victorchanchina@gmail.com
- 方向 深度学习 并行计算 数据挖掘
关于更新
有时间就更新,学到了新东西就更新
作者:Vic_Chan 链接:http://www.jianshu.com/p/699692fdd446 來源:简书 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。