眼下最热门的技术,绝对是人工智能。
人工智能的底层模型是"神经网络"(neural network)。许多复杂的应用(比如模式识别、自动控制)和高级模型(比如深度学习)都基于它。学习人工智能,一定是从它开始。
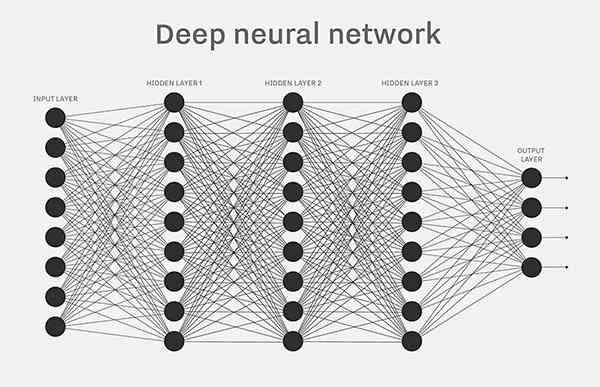
什么是神经网络呢?网上似乎缺乏通俗的解释。
前两天,我读到 Michael Nielsen 的开源教材《神经网络与深度学习》(Neural Networks and Deep Learning),意外发现里面的解释非常好懂。下面,我就按照这本书,介绍什么是神经网络。
这里我要感谢优达学城的赞助,本文结尾有他们的《前端开发(进阶)》课程的消息,欢迎关注。
一、感知器
历史上,科学家一直希望模拟人的大脑,造出可以思考的机器。人为什么能够思考?科学家发现,原因在于人体的神经网络。
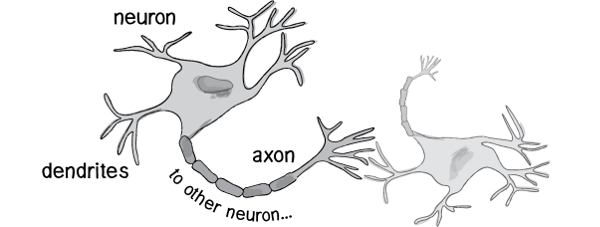
- 外部刺激通过神经末梢,转化为电信号,转导到神经细胞(又叫神经元)。
- 无数神经元构成神经中枢。
- 神经中枢综合各种信号,做出判断。
- 人体根据神经中枢的指令,对外部刺激做出反应。
既然思考的基础是神经元,如果能够"人造神经元"(artificial neuron),就能组成人工神经网络,模拟思考。上个世纪六十年代,提出了最早的"人造神经元"模型,叫做"感知器"(perceptron),直到今天还在用。
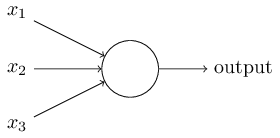
上图的圆圈就代表一个感知器。它接受多个输入(x1,x2,x3...),产生一个输出(output),好比神经末梢感受各种外部环境的变化,最后产生电信号。
为了简化模型,我们约定每种输入只有两种可能:1 或 0。如果所有输入都是1,表示各种条件都成立,输出就是1;如果所有输入都是0,表示条件都不成立,输出就是0。
近期评论