PyTorch 是当前主流深度学习框架之一,其设计追求最少的封装、最直观的设计,其简洁优美的特性使得PyTorch代码更易理解,对新手非常友好。
本文主要介绍深度学习框架中PyTorch部分。
作为具有先进设计理念的框架,PyTorch的历史可追溯到Torch。Torch于2002年诞生于纽约大学,它使用了一种受众面比较小的语言Lua作为接口。Lua具有简洁高效的特点,但由于其过于小众,导致很多人听说要掌握Torch必须新学一门语言而望而却步。
考虑到Python在计算科学领域的领先地位,以及其生态的完整性和接口的易用性,几乎任何框架都不可避免地要提供Python接口。因此,Torch的幕后团队推出了PyTorch。PyTorch不是简单地封装Lua,Torch提供Python接口,而是对Tensor之上的所有模块进行了重构,并新增了最先进的自动求导系统,成为当下最流行的动态图框架。
PyTorch一经推出就立刻引起了广泛关注,并迅速在研究领域流行起来。PyTorch自发布起关注度就在不断上升,截至2017年10月18日,PyTorch的热度已然超越了其他三个框架(Caffe、MXNet和Theano),并且其热度还在持续上升中。
PyTorch的设计思路是线性、直观且易于使用的,当用户执行一行代码时,它会忠实地执行,所以当用户的代码出现缺陷(bug)的时候,可以通过这些信息轻松快捷地找到出错的代码,不会让用户在调试(Debug)的时候因为错误的指向或者异步和不透明的引擎浪费太多的时间。
PyTorch的代码相对于TensorFlow而言,更加简洁直观,同时对于TensorFlow高度工业化的很难看懂的底层代码,PyTorch的源代码就要友好得多,更容易看懂。深入API,理解PyTorch底层肯定是一件令人高兴的事。
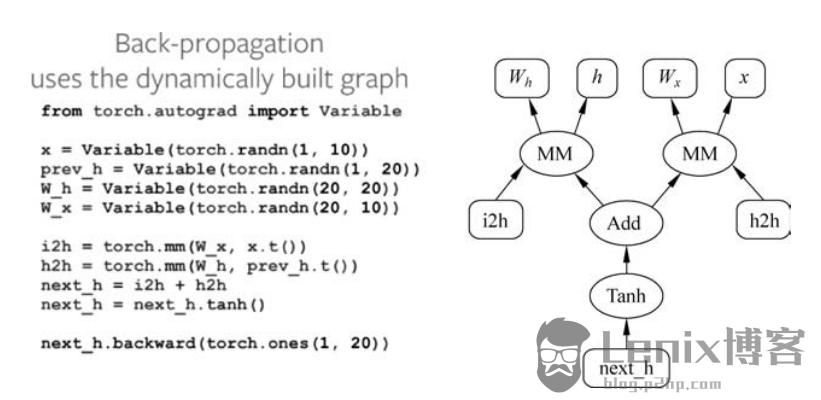
如图2.10和图2.11所示,PyTorch的图是随着代码的运行逐步建立起来的,也就是说,使用者并不需要在一开始就定义好全部的网络结构,而是可以随着编码的进行来一点儿一点儿地调试,相比于TensorFlow和Caffe的静态图而言,这种设计显得更加贴近一般人的编码习惯。