
本文旨在带大家快速入门Go语言,期望小伙伴们在花费十分钟左右通读全文后能对Go语言有一个初步的认知,为后续进一步深入学习Go奠定基础。
本文假设你完全没有接触过Go,你可能是一名精通其他编程语言的程序员,也可能是毫无编程经验、刚刚想转行为码农的热血青年。
编程简介
编程就是生产可在计算机上执行的程序的过程(如下图)。在这个过程中,程序员是“劳动力”,编程语言是工具,可执行的程序是生产结果。而Go语言就是程序员在编程生产过程中使用的一种优秀生产工具。
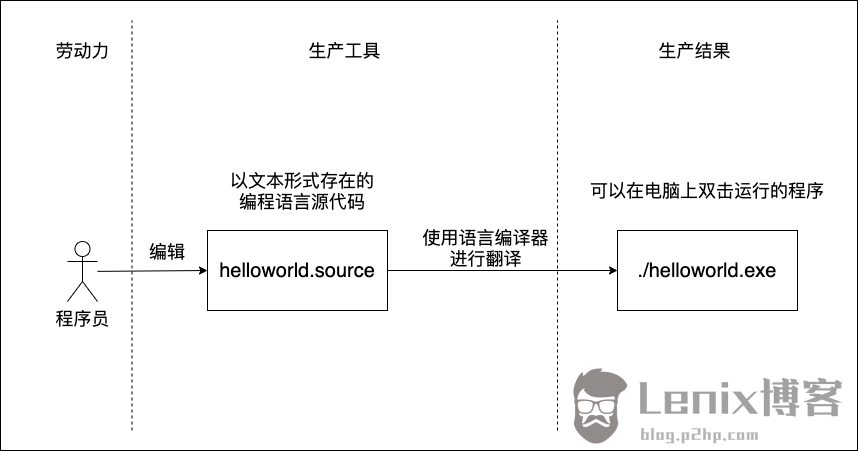
作为“劳动力”的程序员在这个过程中要做的就是使用某种编程语言作为生产工具,将事先设计好的执行逻辑组织和表达出来,这与一个作家将其大脑中设计好的故事情节用人类语言组织和书写在纸上的过程颇为类似(如下图)。
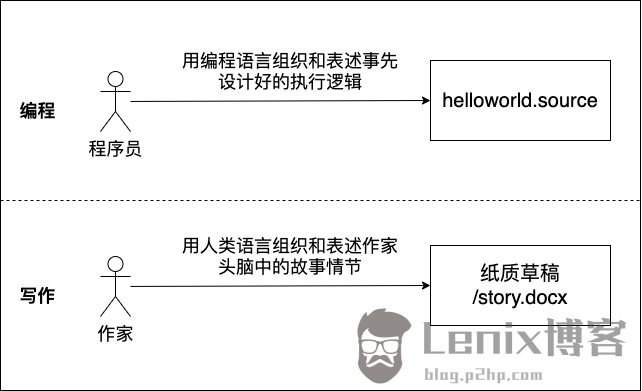
通过这个类比来看,学习一门编程语言,就好比学习一门人类语言,其词汇和语法将是我们的主要学习内容,本文就将围绕Go语言的主要“词汇”和语法形式进行快速说明。
Go简介
Go语言是由Google公司的三位大神级程序员Robert Griesemer、Rob Pike和Ken Thompson在2007年共同开发的一种新的后端编程语言,2009年,Go语言宣布开源。
Go语言的特点是简单易学、静态类型、编译速度快,运行效率高,代码简洁,并且原生支持并发编程。它还支持自动内存管理,可以让开发者更加专注于编程本身,而不用担心内存泄漏的问题。此外,Go语言还支持多核处理器,可以更好地利用多核处理器的优势,提高程序的运行效率。
经过十多年的发展,Go语言现在已经成为一种流行的编程语言,它可以用于开发各种应用程序,包括Web应用、网络服务、系统管理工具、移动应用、游戏开发、数据库管理等。Go语言常用于构建大型分布式系统,以及构建高性能的服务器端应用程序。Go为当前的云原生计算时代开发了一批“杀手级”应用,包括Docker、Kubernetes、Prometheus、InfluxDB、Cilium等。
安装Go
Go是静态语言,需要先编译,再执行,因此在开发Go程序之前,我们首先需要安装Go编译器以及相关工具链。安装的步骤很简单:
- 从Go官网下载最新版本的Go语言安装包 – https://go.dev/dl/
- 解压安装包,并将其复制到您想要安装的位置,例如:/usr/local/go;如果是Windows、MacOS平台,也可以下载图形化安装的安装包;
- 设置环境变量,将Go语言的安装路径添加到PATH变量中;
- 打开终端,输入go version,检查Go语言是否安装成功。如输出类似下面的内容,则表明安装成功!
$go version
go version go1.20 darwin/amd64
注:位于中国大陆的开发者们还需要一个额外的设置:export GOPROXY=’https://goproxy.cn’或将这个设置置于shell配置文件(比如.bashrc)中并使之生效。
第一个Go程序:Hello World
建立一个新目录,并在其中创建新文件helloworld.go,用任意编辑器打开helloworld.go,输入下面Go源码:
//helloworld.go
package main
import "fmt"
func main() {
fmt.Println("Hello, World!")
}
Go支持直接运行某个源文件:
$go run helloworld.go
Hello, World!
但通常我们会先编译这个源文件(helloworld.go),生成可执行的二进制程序(./helloworld),然后再运行它:
$go build -o helloworld helloworld.go
$./helloworld
Hello, World!
Go包(package)
Go包是Go语言中的一种封装技术,它可以将一组Go语言源文件组织成一个可重用的单元,以便在其他Go程序中使用。同属于一个Go包的所有源文件放在一个目录下,并且按惯例该目录的名字与包名相同。以Go标准库的io包为例,其包内的源文件列表如下:
// $GOROOT/src/io目录下的文件列表:
io.go
multi.go
pipe.go
Go包也是Go编译的基本单元,Go编译器可以将包编译为可执行文件(如何该包为main包,且包含main函数实现),也可以编译为可重用的库文件(.a)。
包声明
Go包的声明通常是在每个Go源文件的开头,使用关键字package进行声明,例如:
// mypackage.go
package mypackage
... ...
package的名字按惯例通常为全小写的单个单词或缩略词,比如io、net、os、fmt、strconv、bytes等。
导入Go包
如果要复用已有的Go包,我们需要在源码中导入该包。要导入Go包,可以使用import关键字,例如:
import "fmt" // 导入标准库的fmt包
import "github.com/spf13/pflag" // 导入spf13开源的pflag包
import _ "net/http/pprof" // 导入标准库net/http/pprof包,
// 但不显式使用该包中的类型、变量、函数等标识符
import myfmt "fmt" // 将导入的包重命名为myfmt
Go模块
Go模块(module)是Go语言在1.11版本中引入的新特性,Go module是一组相关的Go package的集合,这个包集合被当做一个独立的单元进行统一版本管理。Go module这种新的依赖管理机制可以让开发者更轻松地管理Go语言项目的依赖关系,并且可以更好地支持多版本的依赖管理。在具有实用价值的Go项目中,我们都会使用Go module进行依赖管理。Go module有版本之分,Go module的版本依赖关系是建立在对语义版本(semver)严格遵守的前提下的。
Go使用go.mod文件来精确记录依赖关系要求,下面是go.mod中依赖关系的操作方法:
$go mod init demo // 创建一个module root为demo的go.mod
$go mod init github.com/bigwhite/mymodule // 创建一个module root为github.com/bigwhite/mymodule的go.mod
$go get github.com/bigwhite/foo@latest // 向go.mod中添加一个依赖包github.com/bigwhite/foo的最新版本
$go get github.com/bigwhite/foo // 与上面命令等价
$go get github.com/bigwhite/foo@v1.2.3 // 显式指定要获取v1.2.3版本
$go mod tidy // 自动添加缺失的依赖包和清理不用的依赖包
$go mod verify // 确认所有依赖都有效
Go最小项目结构
Go官方并没有规定Go项目的标准结构布局,下面是Go核心团队技术负责人Russ Cox推荐的Go最小项目结构:
// 在Go项目仓库根路径下
- go.mod
- LICENSE
- README
- xx.go
- yy.go
... ...
或
// 在Go项目仓库根路径下
- go.mod
- LICENSE
- README
- package1/
- package1.go
- package2/
- package2.go
... ...
变量
Go语言有两种变量声明方式:
- 使用var关键字
使用var关键字进行声明的方式适合所有场合。
var a int // 声明一个int型变量a,初值为0
var b int = 5 // 声明一个int型变量b,初值为5
var c = 6 // Go会根据右值自动为变量c的赋予默认类型,默认的整型为int
var ( // 我们可以将变量声明统一放置在一个var块中,这与上面的声明方式等价
a int
b int = 5
c = 6
)
注:Go变量声明采用变量在前,类型在后的方式,这与C、C 、Java等静态编程语言有较大不同。
- 使用短声明方式声明变量
a := 5 // 声明一个变量a,Go会根据右值自动为变量a的赋予默认类型,默认的整型为int
s := "hello" // 声明一个变量s,Go会根据右值自动为变量s的赋予默认类型,默认的字符串类型为string
注:这种声明方式仅限于在函数或方法内使用,不能用于声明包级变量或全局变量。
常量
Go语言的常量使用const关键字进行声明:
const a int // 声明一个int型常量a,其值为0
const b int = 5 // 声明一个int型常量b,其值为5
const c = 6 // 声明一个常量c,Go会根据右值自动为常量c的赋予默认类型,默认的整型为int
const s = "hello" // 声明一个常量s,Go会根据右值自动为常量s的赋予默认类型,默认的字符串类型为string
const ( // 我们可以将常量声明统一放置在一个const块中,这与上面的声明方式等价
a int
b int = 5
c = 6
s = "hello"
)
类型
Go原生内置了多种基本类型与复合类型。
基本类型
Go原生支持的基本类型包括布尔型、数值类型(整型、浮点型、复数类型)、字符串类型,下面是一些示例:
bool // 布尔类型,默认值false
uint // 架构相关的无符号整型,64位平台上其长度为8字节
int // 架构相关的有符号整型,64位平台上其长度为8字节
uintptr // 架构相关的用于表示指针值的类型,它是一个无符号的整数,大到足以存储一个任意类型的指针的值
uint8 // 架构无关的8位无符号整型
uint16 // 架构无关的16位无符号整型
uint32 // 架构无关的32位无符号整型
uint64 // 架构无关的64位无符号整型
int8 // 架构无关的8位有符号整型
int16 // 架构无关的16位有符号整型
int32 // 架构无关的32位有符号整型
int64 // 架构无关的64位有符号整型
byte // uint8类型的别名
rune // int32类型的别名,用于表示一个unicode字符(码点)
float32 // 单精度浮点类型,满足IEEE-754规范
float64 // 双精度浮点类型,满足IEEE-754规范
complex64 // 复数类型,其实部和虚部均为float32浮点类型
complex128 // 复数类型,其实部和虚部均为float64浮点类型
string // 字符串类型,默认值为""
我们可以使用预定义函数complex来构造复数类型,比如:complex(1.0, -1.4)构造的复数为1 – 1.4i。
复合类型
Go原生支持的复合类型包括数组(array)、切片(slice)、结构体(struct)、指针(pointer)、函数(function)、接口(interface)、map、channel。
数组类型
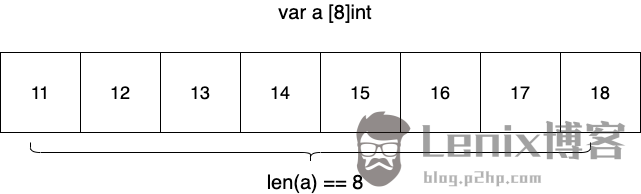
数组类型是一组同构类型元素组成的连续体,它具有固定的长度(length),不能动态伸缩:
[8]int // 一个元素类型为int、长度为16的数组类型
[32]byte // 一个元素类型为byte、长度为32的数组类型
[2]string // 一个元素类型为string、长度为2的数组类型
[N]T // 一个元素类型为T、长度为N的数组类型
通过预定义函数len可以得到数组的长度:
var a = [8]int{11, 12, 13, 14, 15, 16, 17, 18}
println(len(a)) // 8
通过数组下标(从0开始)可以直接访问到数组中的任意元素:
println(a[0]) // 11
println(a[2]) // 13
println(a[7]) // 18
Go支持声明多维数组,即数组的元素类型依然为数组类型:
[2][3][5]float64 // 一个多维数组类型,等价于[2]([3]([5]float64))
切片类型
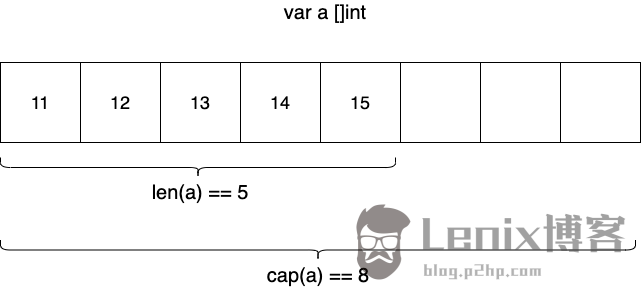
切片类型与数组类型类似,也是同构类型元素的连续体。不同的是切片类型的长度可变,我们在声明切片类型时无需传入长度属性:
[]int // 一个元素类型为int的切片类型
[]string // 一个元素类型为string的切片类型
[]T // 一个元素类型为T的切片类型
[][][]float64 // 多维切片类型,等价于[]([]([]float64))
通过预定义函数len可以得到切片的当前长度:
var sl = []int{11, 12} // 一个元素类型为int的切片,其长度(len)为2, 其值为[11 12]
println(len(sl)) // 2
切片还有一个属性,那就是容量,通过预定义函数cap可以获得其容量值:
println(cap(sl)) // 2
和数组不同,切片可以动态伸缩,Go会根据元素的数量动态对切片容量进行扩展。我们可以通过append函数向切片追加元素:
sl = append(sl, 13) // 向sl中追加新元素,操作后sl为[11 12 13]
sl = append(sl, 14) // 向sl中追加新元素,操作后sl为[11 12 13 14]
sl = append(sl, 15) // 向sl中追加新元素,操作后sl为[11 12 13 14 15]
println(len(sl), cap(sl)) // 5 8 追加后切片容量自动扩展为8
和数组一样,切片也是使用下标直接访问其中的元素:
println(sl[0]) // 11
println(sl[2]) // 13
println(sl[4]) // 15
结构体类型
Go的结构体类型是一种异构类型字段的聚合体,它提供了一种通用的、对实体对象进行聚合抽象的能力。下面是一个包含三个字段的结构体类型:
struct {
name string
age int
gender string
}
我们通常会给这样的一个结构体类型起一个名字,比如下面的Person:
type Person struct {
name string
age int
gender string
}
下面声明了一个Person类型的变量:
var p = Person {
name: "tony bai",
age: 20,
gender: "male",
}
我们可以通过p.FieldName来访问结构体中的字段:
println(p.name) // tony bai
p.age = 21
结构体类型T的定义中可以包含类型为*T的字段成员,但不能递归包含T类型的字段成员:
type T struct {
... ...
p *T // ok
t T // 错误:递归定义
}
Go结构体亦可以在定义中嵌入其他类型:
type F struct {
... ...
}
type MyInt int
type T struct {
MyInt
F
... ...
}
嵌入类型的名字将作为字段名:
var t = T {
MyInt: 5,
F: F {
... ...
},
}
println(t.MyInt) // 5
Go支持不包含任何字段的空结构体:
struct{}
type Empty struct{} // 一个空结构体类型
空结构体类型的大小为0,这在很多场景下很有用(省去了内存分配的开销):
var t = Empty{}
println(unsafe.Sizeof(t)) // 0
指针类型
int类型对应的指针类型为*int,推而广之T类型对应的指针类型为*T。和非指针类型不同,指针类型变量存储的是内存单元的地址,*T指针类型变量的大小与T类型大小无关,而是和系统地址的表示长度有关。
*int // 一个int指针类型
*[4]byte // 一个[4]byte数组指针类型
var a = 6
var p *T // 声明一个T类型指针变量p,默认值为nil
p = &a // 用变量a的内存地址给指针变量p赋值
*p = 7 // 指针解引用,通过指针p将变量a的值由6改为7
n := new(int) // 预定义函数返回一个*int类型指针
arr := new([4]int) // 使用预定义函数new分配一个[4]int数组并返回一个*[4]int类型指针
map类型
map是Go语言提供的一种抽象数据类型,它表示一组无序的键值对,下面定义了一组map类型:
map[string]int // 一个key类型为string,value类型为int的map类型
map[*T]struct{ x, y float64 } // 一个key类型为*T,value类型为struct{ x, y float64 }的map类型
map[string]interface{} // 一个key类型为string,value类型为interface{}的map类型
我们可以用map字面量或make来创建一个map类型实例:
var m = map[string]int{} // 声明一个map[string]int类型变量并初始化
var m1 = make(map[string]int) // 与上面的声明等价
var m2 = make(map[string]int, 100) // 声明一个map[string]int类型变量并初始化,其初始容量建议为100
操作map变量的方法也很简单:
m["key1"] = 5 // 添加/设置一个键值对
v, ok := m["key1"] // 获取“key1”这个键的值,如果存在,则其值存储在v中,ok为true
delete(m, "key1") // 从m这个map中删除“key1”这个键以及其对应的值
其他类型
函数、接口、channel类型在后面有详细说明。
自定义类型
使用type关键字可以实现自定义类型:
type T1 int // 定义一个新类型T1,其底层类型(underlying type)为int
type T2 string // 定义一个新类型T2,其底层类型为string
type T3 struct{ // 定义一个新类型T3,其底层类型为一个结构体类型
x, y int
z string
}
type T4 []float64 // 定义一个新类型T4,其底层类型为[]float64切片类型
type T5 T4 // 定义一个新类型T5,其底层类型为[]float64切片类型
Go也支持为类型定义别名(alias),其形式如下;
type T1 = int // 定义int的类型别名为T1,T1与int等价
type T2 = string // 定义string的类型别名为T2,T2与string等价
type T3 = T2 // 定义T的类型别名为T3,T3与T2等价,也与string等价
类型转换
Go不支持隐式自动转型,如果要进行类型转换操作,我们必须显式进行,即便两个类型的底层类型相同也需如此:
type T1 int
type T2 int
var t1 T1
var n int = 5
t1 = T1(n) // 显式将int类型变量转换为T1类型
var t2 T2
t2 = T2(t1) // 显式将T1类型变量转换为T2类型
Go很多原生类型支持相互转换:
// 数值类型的相互转换
var a int16 = 16
b := int32(a)
c := uint16(a)
f := float64(a)
// 切片与数组的转换(Go 1.17版本及后续版本支持)
var a [3]int = [3]int([]int{1,2,3}) // 切片转换为数组
var pa *[3]int = (*[3]int)([]int{1,2,3}) // 切片转换为数组指针
sl := a[:] // 数组转换为切片
// 字符串与切片的相互转换
var sl = []byte{'h', 'e','l', 'l', 'o'}
var s = string(sl) // s为hello
var sl1 = []byte(s) // sl1为['h' 'e' 'l' 'l' 'o']
string([]rune{0x767d, 0x9d6c, 0x7fd4}) // []rune切片到string的转换
控制语句
Go提供了常见的控制语句,包括条件分支(if)、循环语句(for)和选择分支语句(switch)。
条件分支语句
// if ...
if a == 1 {
... ...
}
// if - else if - else
if a == 1 {
} else if b == 2 {
} else {
}
// 带有条件语句自用变量
if a := 1; a != 0 {
}
// if语句嵌套
if a == 1 {
if b == 2 {
} else if c == 3 {
} else {
}
}
循环语句
// 经典循环
for i := 0; i < 10; i {
...
}
// 模拟while ... do
for i < 10 {
}
// 无限循环
for {
}
// for range
var s = "hello"
for i, c := range s {
}
var sl = []int{... ...}
for i, v := range sl {
}
var m = map[string]int{}
for k, v := range m {
}
var c = make(chan int, 100)
for v := range c {
}
选择分支语句
var n = 5
switch n {
case 0, 1, 2, 3:
s1()
case 4, 5, 6, 7:
s2()
default: // 默认分支
s3()
}
switch n {
case 0, 1:
fallthrough // 显式告知执行下面分支的动作
case 2, 3:
s1()
case 4, 5, 6, 7:
s2()
default:
s3()
}
switch x := f(); {
case x < 0:
return -x
default:
return x
}
switch {
case x < y:
f1()
case x < z:
f2()
case x == 4:
f3()
}
函数
Go使用func关键字来声明一个函数:
func greet(name string) string {
return fmt.Sprintf("Hello %s", name)
}
函数由函数名、可选的参数列表和返回值列表组成。Go函数支持返回多个返回值,并且我们通常将表示错误值的返回类型放在返回值列表的最后面:
func Atoi(s string) (int, error) {
... ...
return n, nil
}
在Go中函数是一等公民,因此函数自身也可以作为参数或返回值:
func MultiplyN(n int) func(x int) int {
return func(x int) int {
return x * n
}
}
像上面MultiplyN函数中定义的匿名函数func(x int) int,它的实现中引用了它的外围函数MultiplyN的参数n,这样的匿名函数也被称为闭包(closure)。
说到函数,我们就不能不提defer。在某函数F调用的前面加上defer,该函数F的执行将被“延后”至其调用者A结束之后:
func F() {
fmt.Println("call F")
}
func A() {
fmt.Println("call A")
defer F()
fmt.Println("exit A")
}
func main() {
A()
}
上面示例输出:
call A
exit A
call F
在一个函数中可以多次使用defer:
func B() {
defer F()
defer G()
defer H()
}
被defer修饰的函数将按照“先入后出”的顺序在B函数结束后被调用,上面B函数执行后将输出:
call H
call G
call F
方法
方法是带有receiver的函数。下面是Point类型的一个方法Length:
type Point struct {
x, y float64
}
func (p Point) Length() float64 {
return math.Sqrt(p.x * p.x p.y * p.y)
}
而在func关键字与函数名之间的部分便是receiver。这个receiver也是Length方法与Point类型之间纽带。我们可以通过Point类型变量来调用Length方法:
var p = Point{3,4}
fmt.Println(p.Length())
亦可以将方法当作函数来用:
var p = Point{3,4}
fmt.Println(Point.Length(p)) // 这种用法也被称为方法表达式(method expression)
接口
接口是一组方法的集合,它代表一个“契约”,下面是一个由三个方法组成的方法集合的接口类型:
type MyInterface interface {
M1(int) int
M2(string) error
M3()
}
Go推崇面向接口编程,因为通过接口我们可以很容易构建低耦合的应用。
Go还支持在接口类型(如I)中嵌套其他接口类型(如io.Writer、sync.Locker),其结果就是新接口类型I的方法集合为其方法集合与嵌入的接口类型Writer和Locker的方法集合的并集:
type I interface { // 一个嵌入了其他接口类型的接口类型
io.Writer
sync.Locker
}
接口实现
如果一个类型T实现了某个接口类型MyInterface方法集合中的所有方法,那么我们说该类型T实现了接口MyInterface,于是T类型的变量t可以赋值给接口类型MyInterface的变量i,此时变量i的动态类型为T:
var t T
var i MyInterface = t // ok
通过上述变量i可以调用T的方法:
i.M1(5)
i.M2("demo")
i.M3()
方法集合为空的接口类型interface{}被称为“空接口类型”,空白的“契约”意味着任何类型都实现了该空接口类型,即任何变量都可以赋值给interface{}类型的变量:
var i interface{} = 5 // ok
i = "demo" // ok
i = T{} // ok
i = &T{} // ok
i = []T{} // ok
注:Go 1.18中引入的新预定义标识符any与interface{}是等价类型。
接口的类型断言
Go支持通过类型断言从接口变量中提取其动态类型的值:
v, ok := i.(T) // 类型断言
如果接口变量i的动态类型确为T,那么v将被赋予该动态类型的值,ok为true;否则,v为T类型的零值,ok为false。
类型断言也支持下面这种语法形式:
v := i.(T)
但在这种形式下,一旦接口变量i之前被赋予的值不是T类型的值,那么这个语句将抛出panic。
接口类型的type switch
“type switch”这是一种特殊的switch语句用法,仅用于接口类型变量:
func main() {
var x interface{} = 13
switch x.(type) {
case nil:
println("x is nil")
case int:
println("the type of x is int") // 执行这一分支case
case string:
println("the type of x is string")
case bool:
println("the type of x is string")
default:
println("don't support the type")
}
}
switch关键字后面跟着的表达式为x.(type),这种表达式形式是switch语句专有的,而且也只能在switch语句中使用。这个表达式中的x必须是一个接口类型变量,表达式的求值结果是这个接口类型变量对应的动态类型。
上述例子中switch后面的表达式也可由x.(type)换成了v := x.(type)。v中将存储变量x的动态类型对应的值信息:
var x interface{} = 13
switch x.(type) {
case nil:
println("v is nil")
case int:
println("the type of v is int, v =", v) // 执行这一分支case,v = 13
... ...
}
泛型
Go从1.18版本开始支持泛型。Go泛型的基本语法是类型参数(type parameter),Go泛型方案的实质是对类型参数的支持,包括:
- 泛型函数(generic function):带有类型参数的函数;
- 泛型类型(generic type):带有类型参数的自定义类型;
- 泛型方法(generic method):泛型类型的方法。
泛型函数
下面是一个泛型函数max的定义:
type ordered interface {
~int | ~int8 | ~int16 | ~int32 | ~int64 |
~uint | ~uint8 | ~uint16 | ~uint32 | ~uint64 | ~uintptr |
~float32 | ~float64 |
~string
}
func max[T ordered](sl []T) T {
... ...
}
与普通Go函数相比,max函数在函数名称与函数参数列表之间多了一段由方括号括起的代码:[T ordered];max参数列表中的参数类型以及返回值列表中的返回值类型都是T,而不是某个具体的类型。
max函数中多出的[T ordered]就是Go泛型的类型参数列表(type parameters list),示例中这个列表中仅有一个类型参数T,ordered为类型参数的类型约束(type constraint)。
我们可以像普通函数一样调用泛型函数,我们可以显式指定类型实参:
var m int = max[int]([]int{1, 2, -4, -6, 7, 0}) // 显式指定类型实参为int
fmt.Println(m) // 输出:7
Go也支持自动推断出类型实参:
var m int = max([]int{1, 2, -4, -6, 7, 0}) // 自动推断T为int
fmt.Println(m) // 输出:7
泛型类型
所谓泛型类型,就是在类型声明中带有类型参数的Go类型:
type Set[T comparable] map[T]string
type element[T any] struct {
next *element[T]
val T
}
type Map[K, V any] struct {
root *node[K, V]
compare func(K, K) int
}
以泛型类型Set为例,其使用方法如下:
var s = Set[string]{}
s["key1"] = "value1"
println(s["key1"]) // value1
泛型方法
Go类型可以拥有自己的方法(method),泛型类型也不例外,为泛型类型定义的方法称为泛型方法(generic method)。
type Set[T comparable] map[T]string
func (s Set[T]) Insert(key T, val string) {
s[key] = val
}
func (s Set[T]) Get(key T) (string, error) {
val, ok := s[key]
if !ok {
return "", errors.New("not found")
}
return val, nil
}
func main() {
var s = Set[string]{
"key": "value1",
}
s.Insert("key2", "value2")
v, err := s.Get("key2")
fmt.Println(v, err) // value2
}
类型约束
Go通过类型约束(constraint)对泛型函数的类型参数以及泛型函数中的实现代码设置限制。Go使用扩展语法后的interface类型来定义约束。
下面是使用常规接口类型作为约束的例子:
type Stringer interface {
String() string
}
func Stringify[T fmt.Stringer](s []T) (ret []string) { // 通过Stringer约束了T的实参只能是实现了Stringer接口的类型
for _, v := range s {
ret = append(ret, v.String())
}
return ret
}
Go接口类型声明语法做了扩展,支持在接口类型中放入类型元素(type element)信息:
type ordered interface {
~int | ~int8 | ~int16 | ~int32 | ~int64 |
~uint | ~uint8 | ~uint16 | ~uint32 | ~uint64 | ~uintptr |
~float32 | ~float64 | ~string
}
func Less[T ordered](a, b T) bool {
return a < b
}
type Person struct {
name string
age int
}
func main() {
println(Less(1, 2)) // true
println(Less(Person{"tony", 11}, Person{"tom", 23})) // Person不满足ordered的约束,会导致编译错误
}
并发
Go语言原生支持并发,Go并没有使用操作系统线程作为并发的基本执行单元,而是实现了goroutine这一由Go运行时(runtime)负责调度的、轻量的用户级线程,为并发程序设计提供原生支持。
goroutine
通过go关键字 函数/方法的方式,我们便可以创建一个goroutine。创建后,新goroutine将拥有独立的代码执行流,并与创建它的goroutine一起被Go运行时调度。
go fmt.Println("I am a goroutine")
// $GOROOT/src/net/http/server.go
c := srv.newConn(rw)
go c.serve(connCtx)
goroutine的执行函数返回后,goroutine便退出。如果是主goroutine(执行main.main的goroutine)退出,那么整个Go应用进程将会退出,程序生命周期结束。
channel
Go提供了原生的用于goroutine之间通信的机制channel,channel的定义与操作方式如下:
// channel类型
chan T // 一个元素类型为T的channel类型
chan<- float64 // 一个元素类型为float64的只发送channel类型
<-chan int // 一个元素类型为int的只接收channel类型
var c chan int // 声明一个元素类型为int的channel类型的变量,初值为nil
c1 := make(chan int) // 声明一个元素类型为int的无缓冲的channel类型的变量
c2 := make(chan int, 100) // 声明一个元素类型为int的带缓冲的channel类型的变量,缓冲大小为100
close(c) // 关闭一个channel
下面是两个goroutine基于channel通信的例子:
func main() {
var c = make(chan int)
go func(a, b int) {
c <- a b
}(3,4)
println(<-c) // 7
}
当涉及同时对多个channel进行操作时,Go提供了select机制。通过select,我们可以同时在多个channel上进行发送/接收操作:
select {
case x := <-ch1: // 从channel ch1接收数据
... ...
case y, ok := <-ch2: // 从channel ch2接收数据,并根据ok值判断ch2是否已经关闭
... ...
case ch3 <- z: // 将z值发送到channel ch3中:
... ...
default: // 当上面case中的channel通信均无法实施时,执行该默认分支
}
错误处理
Go提供了简单的、基于错误值比较的错误处理机制,这种机制让每个开发人员必须显式地去关注和处理每个错误。
error类型
Go用error这个接口类型表示错误,并且按惯例,我们通常将error类型返回值放在返回值列表的末尾。
// $GOROOT/src/builtin/builtin.go
type error interface {
Error() string
}
任何实现了error的Error方法的类型的实例,都可以作为错误值赋值给error接口变量。
Go提供了便捷的构造错误值的方法:
err := errors.New("your first demo error")
errWithCtx = fmt.Errorf("index %d is out of bounds", i)
错误处理形式
Go最常见的错误处理形式如下:
err := doSomething()
if err != nil {
... ...
return err
}
通常我们会定义一些“哨兵”错误值来辅助错误处理方检视(inspect)错误值并做出错误处理分支的决策:
// $GOROOT/src/bufio/bufio.go
var (
ErrInvalidUnreadByte = errors.New("bufio: invalid use of UnreadByte")
ErrInvalidUnreadRune = errors.New("bufio: invalid use of UnreadRune")
ErrBufferFull = errors.New("bufio: buffer full")
ErrNegativeCount = errors.New("bufio: negative count")
)
func doSomething() {
... ...
data, err := b.Peek(1)
if err != nil {
switch err {
case bufio.ErrNegativeCount:
// ... ...
return
case bufio.ErrBufferFull:
// ... ...
return
case bufio.ErrInvalidUnreadByte:
// ... ...
return
default:
// ... ...
return
}
}
... ...
}
Is和As
从Go 1.13版本开始,标准库errors包提供了Is函数用于错误处理方对错误值的检视。Is函数类似于把一个error类型变量与“哨兵”错误值进行比较:
// 类似 if err == ErrOutOfBounds{ … }
if errors.Is(err, ErrOutOfBounds) {
// 越界的错误处理
}
不同的是,如果error类型变量的底层错误值是一个包装错误(Wrapped Error),errors.Is方法会沿着该包装错误所在错误链(Error Chain),与链上所有被包装的错误(Wrapped Error)进行比较,直至找到一个匹配的错误为止。
标准库errors包还提供了As函数给错误处理方检视错误值。As函数类似于通过类型断言判断一个error类型变量是否为特定的自定义错误类型:
// 类似 if e, ok := err.(*MyError); ok { … }
var e *MyError
if errors.As(err, &e) {
// 如果err类型为*MyError,变量e将被设置为对应的错误值
}
如果error类型变量的动态错误值是一个包装错误,errors.As函数会沿着该包装错误所在错误链,与链上所有被包装的错误的类型进行比较,直至找到一个匹配的错误类型,就像errors.Is函数那样。
小结
读到这里,你已经对Go语言有了入门级的认知,但要想成为一名Gopher(对Go开发人员的称呼),还需要更进一步的学习与实践。我的极客时间专栏《Go语言第一课》是一个很好的起点,欢迎大家订阅学习^_^。
BTW,本文部分内容由ChatGPT生成!你能猜到是哪些部分吗^_^。







