PHP有一个数据结构来统治它们。数组是一个复杂,灵活,无主的混合数据结构,它结合了列表(list)和链接映射(linked ma)的行为。但是我们将它用于一切,因为PHP是务实的:“ 以一种基于实际而非理论考虑的方式理性和现实地处理事物 ”。一个数组能够完成任务。不幸的是,灵活性带来了复杂性
最近发布的PHP 7在PHP社区中引起了很多兴奋。我们迫不及待地开始使用新功能并尝试报告的~2x性能提升。其中一个原因,它运行得更快是因为数组进行了重新设计。但它仍然是相同的结构,“ 针对一切进行了优化; 没有东西进行优化“有改进的余地。
“ SPL数据结构怎么样?”
不幸的是他们太可怕了。他们确实在PHP 7之前提供了一些好处,但后来被忽略到没有实际价值的程度。
“为什么我们不能修复和改进它们?”
我们可以,但我相信他们的设计和实现非常糟糕,用更新的东西替换它们会更好。
“SPL数据结构设计非常糟糕。” - Anthony Ferrara
这里介绍一下ds,PHP 7的扩展,提供专门的数据结构作为数组的替代。
本文简要介绍了每个数据结构的行为和性能优势。最后还有一系列预期问题的答案。
Github: https://github.com/php-ds
命名空间: Ds\
接口:Collection, Sequence, Hashable
类:Vector, Deque, Map, Set, Stack, Queue, PriorityQueue, Pair
Collection
Collection是基本接口,涵盖常见功能,如foreach,echo,count,print_r,var_dump,serialize,json_encode和clone。
序列Sequence
序列描述了在单个线性维度中排列的值的行为。有些语言将此称为List。它类似于使用增量整数键的数组,但有一些特性除外:
- 值将始终索引为[0,1,2,...,size - 1]。
- 删除或插入会更新所有连续值的位置。
- 仅允许按[0,size - 1]范围内的索引访问值。
向量Vector
向量是一个序列(Sequence)值的,生长和收缩自动的连续缓冲器。它是最有效的顺序结构,因为值的索引是到缓冲区中其索引的直接映射,并且增长因子不绑定到特定的倍数或指数。
优势
- 内存使用率非常低
- get,set,push和pop是O(1)
弱点
- insert,remove,shift,和unshift是O(n)的
Photoshop中使用的头号数据结构是矢量。“ - Sean Parent,CppCon 2015
双端队列Deque
Deque(发音“deck”) 是一个序列(Sequence)值的,生长和收缩自动的连续缓冲器。该名称是“ 双端队列”的通用缩写,由Ds\Queue内部使用。
两个指针用于跟踪头部和尾部。指针可以“环绕”缓冲区的末端,这避免了移动其他值以腾出空间的需要。这使得shift和unshift速度非常快-矢量不能与之抗衡。
通过索引访问值需要索引与其在缓冲区中的相应位置之间的转换:((head + position)%capacity)。
优势
- 内存使用率低
- get, set,PUSH,POP,shift,并且unshift都是O(1)
弱点
- 插入,删除是O(n)
- 缓冲容量必须是2的幂。
以下基准测试显示了用于push 2ⁿ 随机整数所花费的总时间和内存。PHP数组,Ds的\矢量和Ds的\ deque的都很快,但SplDoublyLinkedList总是 慢2倍多。
SplDoublyLinkedList分别为每个值分配内存,因此预计会出现线性内存增长。数组和Ds的\的Deque具有2.0的生长因子以维持2ⁿ容量。Ds \ Vector的增长因子为1.5,这导致更多的分配,但整体内存使用率更低。


以下基准测试显示到所花费的时间unshift单个值成2ⁿ值的序列。设置样本所需的时间不包括在基准测试中。
它表明array_unshift是O(n)。每次样本量增加一倍,unshift所需的时间也会增加一倍。这是有道理的,因为必须更新[1,size - 1]范围内的每个数字索引。
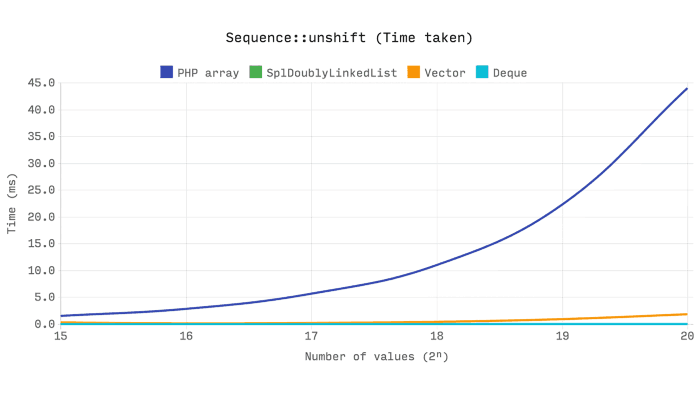
但是Ds \ Vector :: unshift也是O(n),为什么它会这么快?请记住,数组会将每个值与其哈希和键一起存储在存储桶中。因此,如果索引是数字,我们必须检查每个桶并更新其哈希值。在内部,array_unshift实际上 分配了一个全新的数组来执行此操作,并在复制了所有值时替换旧的数组。
Vector中值的索引是缓冲区中其索引的直接映射,因此我们需要做的就是将范围[1,size - 1]中的每个值向右移动一个位置。在内部,这是使用单个memmove操作完成的。
这两个Ds的\的Deque和SplDoublyLinkedList是非常快的,因为它unshift的值需要的时间不会受到样本量影响,即 O(1)
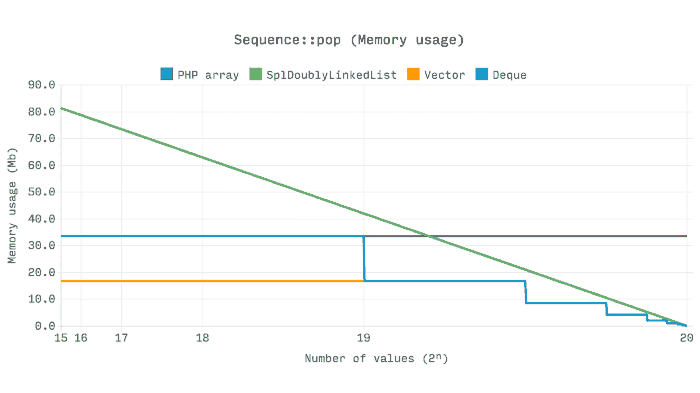
以下基准测试显示了内存使用情况如何受2ⁿ pop操作的影响,或者从2ⁿ的大小到零。
这里有趣的是,数组总是保持分配的内存,即使它的大小显着减少。如果Ds \ Vector和Ds \ Deque的大小低于当前容量的四分之一,它们的分配容量会减半。SplDoublyLinkedList将释放每个值的内存,这就是我们可以看到线性下降的原因。
栈Stack
栈 是一个“后进先出”或“ LIFO ”结构,其仅允许在该顺序的结构和迭代的顶部获得的值,破坏性。
Ds\Stack内部使用Ds\Vector。
SplStack扩展了SplDoublyLinkedList,因此性能比较等同于将Ds \ Vector与SplDoublyLinkedList进行比较, 如前面的基准测试所示。以下基准测试显示执行2ⁿ pop操作所需的时间,或从2ⁿ的大小到零。

队列Queue
队列 是一个“先入先出”或“FIFO ” 结构,其仅允许在该顺序队列和迭代的前端获得的值,破坏性。
Ds \ Queue 在内部使用Ds \ Deque。SplQueue扩展了SplDoublyLinkedList,因此性能比较等同于将Ds \ Deque与SplDoublyLinkedList进行比较, 如前面的基准测试中所示。
优先级队列PriorityQueue
PriorityQueue是非常类似于一个队列。值以指定的优先级推入队列,具有最高优先级的值将始终位于队列的前面。对PriorityQueue进行迭代是破坏性的,相当于连续的pop操作,直到队列为空。
使用最大堆(max heap)实现。
首先,对具有相同优先级的值保留先排序(first in, first out ordering is preserved for values with the same priority),因此具有相同优先级的多个值的行为与 Queue完全相同。另一方面, SplPriorityQueue将以任意顺序移除值。
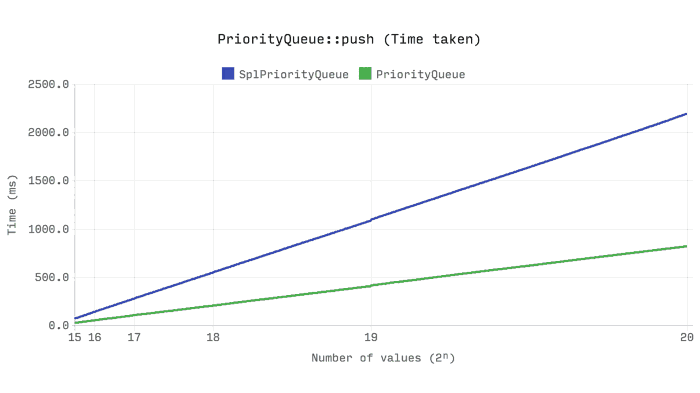
以下基准测试显示了将具有随机优先级的2ⁿ随机整数push 队列所花费的时间和内存。每个基准测试使用相同的随机数,并且队列基准测试 也会生成随机优先级,即使它不用于任何事情。
这可能是所有的基准最显著... Ds\PriorityQueue 比 SplPriorityQueue快两倍以上,并且只使用它5%的内存。这是20倍的内存效率。
但是怎么样?当SplPriorityQueue也使用类似的内部结构时,差异如何呢?这一切都归结为值如何与优先级配对。SplPriorityQueue允许将任何类型的值用作优先级,这意味着每个优先级对占用32个字节。
Ds\PriorityQueue仅支持整数优先级,因此每对只分配24个字节。但这并没有足够的差异来解释结果。
如果你看一看SplPriorityQueue ::insert的 源码 ,你会发现,它实际上分配一个array来存储对(pair)。
因为数组的最小容量为8,所以每对实际分配zval + HashTable + 8 *(Bucket + hash)+ 2 * zend_string +(8 + 16)字节 字符串有效负载=16 + 56 + 36 * 8 + 2 * 24 + 8 + 16 = 432字节 (64位)。
“那么......为什么一个数组?”
SplPriorityQueue使用与SplMaxHeap相同的内部结构,这要求值必须是zval。创建一个也是zval本身的zval对儿的一种明显(但效率低)的方法是使用数组。

可哈希Hashable
允许将对象用作键的接口。它是spl_object_hash的替代方法,它根据其句柄确定对象的哈希值:这意味着被隐式定义视为相等的两个对象不会被视为相等,因为它们不是同一个实例。
Hashable只引入了两种方法:hash和equals。许多其他语言本身支持这个,如Java的hashCode和equals,或Python的__hash__和__eq__。已经有一些RFC将其添加到PHP但没有一个被接受。
如果对象键未实现Hashable,则所有支持此接口的结构都将回退到spl_object_hash。
尊重Hashable接口的数据结构是Map和Set。
图Map
Map是键-值对的有序集合,在相似的上下文中使用时几乎等同于一个数组。键可以是任何类型,但必须是唯一的。如果使用相同的键添加到map中,则替换值。
像数组一样,保留了插入顺序。
优势
- 性能和内存效率几乎与数组相同。
- 当分配的内存足够低时自动释放分配的内存。
- 键和值可以是任何类型,包括对象。
- put,get,remove和hasKey是O(1)
弱点
- 当对象用作键时,无法转换为数组。
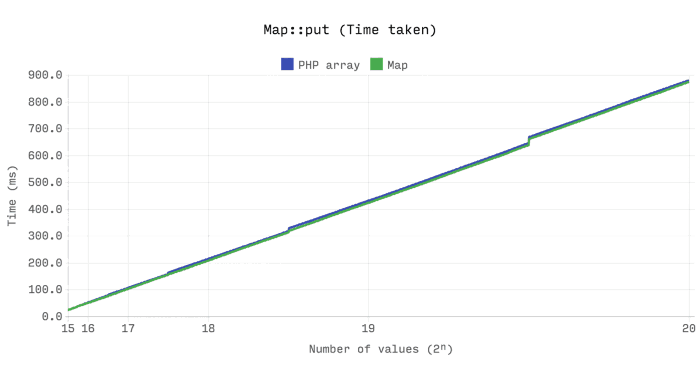
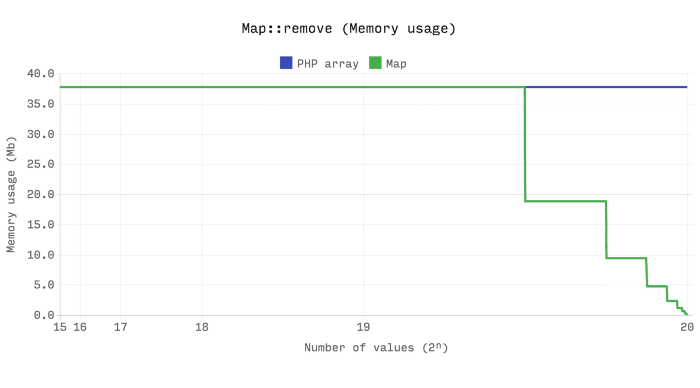
以下基准测试表明,数组和Ds\Map之间的性能和内存效率非常相似。但是,数组将始终保持已分配的内存,Ds\Map将在其大小低于其容量的四分之一时释放已分配的内存。
Set(集合)
Set是一组唯一值(A Set is a collection of unique values.)除非实现另有说明,否则set的教科书定义将表明值是无序的。以Java为例,java.util.Set是一个具有两个主要实现的接口:HashSet和TreeSet。HashSet提供O(1)添加和删除,其中TreeSet确保排序集但O(log n) 添加和删除。
Set使用与Map相同的内部结构,它基于与数组相同的结构。这意味着Set可以在需要时按O(n * log(n))时间排序 ,就像Map和数组一样。
优势
- 添加,删除,和包含(contains)是O(1)
- 尊重Hashable接口。
- 支持任何类型的值(SplObjectStorage仅支持对象)。
弱点
- 不支持push,pop,insert,shift或unshift。
- 如果在索引之前有删除的值,则get为O(n),否则为O(1)。
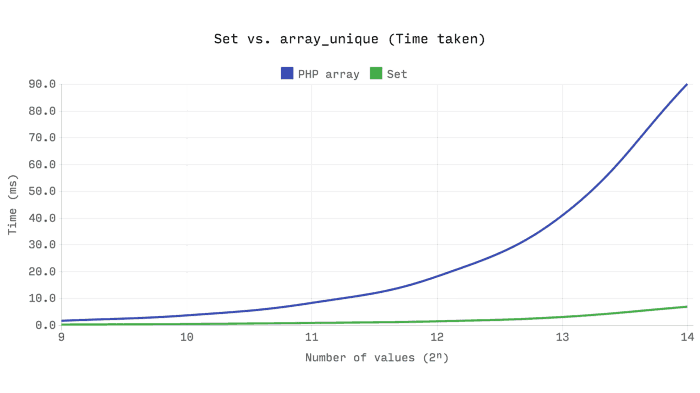
以下基准测试显示了添加2的n次方新stdClass实例所需的时间。这表明,Ds\Set是比SplObjectStorage稍快,并使用约一半的内存。


创建唯一值数组的常用方法是使用array_unique,它创建一个仅包含唯一值的新数组。这里要记住的一件重要事情是数组中的值没有被索引,因此in_array是线性搜索,O(n)。因为array_unique处理值而不是键,所以每个成员资格测试都是线性搜索,结果是O( n² )。
回应预期的问题和意见
有测试吗?
现在有~ 2400个测试。有些测试可能是多余的,但我宁愿间接测试同样的事情两次而不是完全没有。
我们能看到基准测试是如何配置的吗?还有更多吗?
您可以在专用基准测试库中找到完整的可配置基准测试列表:php-ds / benchmarkmarks。
所有特色基准测试都是在2015 Macbook Pro上使用默认的PHP 7.0.3版本创建的。结果将因版本和平台而异。
为什么Stack , Queue , Set 和 Map 不是接口?
我不相信他们中的任何一个都有其他值得包括的实现。在我看来,引入3个接口和7个类是实用主义和专业化之间的良好平衡。
我什么时候应该使用Deque 而不是Vector?
如果您确定不会使用shift和unshift,请使用Vector。您可以使用Sequence作为typehint来接受其中之一。
为什么所有class都是final的?
SPL结构是如何滥用继承的一个很好的例子,例如。SplStack扩展了SplDoublyLinkedList,它支持索引,shift和unshift的随机访问-所以它在技术上不是一个栈。
Java Collections Framework还有一些有趣的案例,其中继承会导致歧义。一个ArrayDeque具有附加值的三种方法:add,addLast,和push。这并不是一件坏事,因为ArrayDeque实现了Deque和Queue,这就是为什么它必须实现addLast和push。但是,有三种方法可以做同样的事情会导致混淆和不一致。
旧的java.util.Stack扩展了java.util.Vector,并 声明“Deque接口及其实现提供了一组更完整,更一致的LIFO栈操作”,但Deque接口包含addFirst和remove(x)等方法,它不应该是栈 API的一部分。
仅仅因为这些结构不相互延伸并不意味着我们也不应该被允许。
这实际上是一个公平的观点,但我仍然认为组合更适合数据结构。它们被设计成独立的,就像数组一样。您无法扩展数组,因此我们使用内部数组来存储实际数据,从而围绕它设计自己的API 。
继承还会带来不必要的内部复杂性。
为什么没有链表?
LinkedList实际上是第一个数据结构,因为它似乎是一个良好的开端。当我意识到在任何情况下都无法与Vector或Deque竞争时,我决定删除它。支持这个的两个主要原因是分配开销和引用局部性。
链表必须或者分配或释放存储器每当值被添加或移除。一个节点(node)还有两个指针(在双向链表的情况下)引用之前的另一个节点,以及之后的节点。Vector和Deque都预先分配了一个内存缓冲区,因此不需要经常分配和释放。他们也不需要额外的指针来了解前一个或另一个之后的值,因此开销较少。
链表是否会有较低的峰值内存,因为没有缓冲区?
只有当集合非常小时。Vector的内存使用量的上限是((1.5 *(size -1))* zval)个字节,最小值为10 * zval。双向链表将使用(size*(zval + 8 + 8))个字节,所以仅其size小于6时将比矢量使用较少的内存。
好的...所以链表使用更多内存。但为什么它会变慢?
链表的节点具有糟糕的空间局部性。这意味着节点的物理内存位置可能远离其相邻节点。因此,通过链表进行迭代会在内存中跳转而不是使用CPU缓存。这是Vector和Deque都具有显着优势的地方:值在物理上彼此相邻。
“不连续的数据结构是所有表现邪恶的根源。具体来说,请对链表说不。“
“对于实际现代微处理器的性能而言,几乎没有什么比使用链表数据结构更有害了。”
- Chandler Carruth(CppCon 2014)
PHP是一种Web开发语言 - 性能并不重要。
性能不应该是您的首要任务。代码应该是一致的,可维护的,健壮的,可预测的,安全的,易于理解的。但这并不是说性能“不重要”。
我们花了很多时间来减少资产规模,基准测试框架,并发布毫无意义的微观优化:
PHP 7带来的性能提升约2倍让我们都非常渴望尝试它。它可以说是从PHP 5转换来最常见的好处之一。
高效的代码可以减轻我们服务器的负担,缩短API和网页的响应时间,并缩短开发工具的运行时间。性能很重要,但可维护的代码应该是第一位的。
💬 讨论:Twitter,Reddit,StackOverflow
🔎 探索:github.com/php-ds
📊 基准:github.com/php-ds/benchmarks
via https://medium.com/@rtheunissen/efficient-data-structures-for-php-7-9dda7af674cd
最后更新于 2021年12月5日