-问题起因
近期线上一组服务中,个别节点服务器CPU使用率很低,只有其他1/4。排除业务不均,曾怀疑是系统top统计错误,从 Erlang调度器的利用率调查 找到通过erlang:statistics(scheduler_wall_time) 查看服务器CPU低的机器调度器实际的CPU利用率很高接近100%,而其他机器都不到30%。
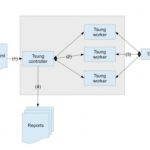
分析不同业务服务,发现只有在node 中进程数采用调度器CPU利用低这个问题。
- 高利用率
 View Code
View Code- 低利用率
View Code-Whatsapp 案例
erlang方面能找到案例不多,幸运的发现whatsapp 给出了类似案例详细的分析:
First bottleneck showed up at 425K. System ran into a lot of contention. Work stopped.Instrumented the scheduler to measure how much useful work is being done, or sleeping, or spinning.Under load it started to hit sleeping locks so 35-45% CPU was being used across the system but the schedulers are at 95% utilization.
-工具分析
通过微博私信,请教了下郑思瑶,推荐VTune分析,推测是大量进程时调度器消耗过大。
通过Intel 官方网站,填写注册信息,会立即回复邮件下载地址,并给30天试用期。
速度很慢,建议挂着VPN下载;VTune 的linux版本命令行模式使用很简单:
tar -zxf vtune_amplifier_xe_2015.tar.gz
cd vtune_amplifier_xe_2015
./install.sh
cd /opt/intel/vtune_amplifier_xe_2015.1.0.367959/
source amplxe-vars.sh
amplxe-cl -collect lightweight-hotspots -run-pass-thru=--no-altstack -target-pid=1575
amplxe-cl -report hotspots
可直接线上执行,不影响服务正常运行,得到如下结果:

Summary ------- Elapsed Time: 19.345 CPU Time: 182.023 Average CPU Usage: 9.155 CPI Rate: 1.501 Function Module CPU Time:Self ------------------------------------------- ------------------ ------------- sched_spin_wait beam.smp 72.754 raw_local_irq_enable vmlinux 19.282 process_main beam.smp 10.476 ethr_native_atomic32_read beam.smp 8.337 func@0xffffffff8100af60 vmlinux 3.007 __pthread_mutex_lock libpthread-2.12.so 2.342 raw_local_irq_restore vmlinux 1.973 __sched_yield libc-2.12.so 1.913 pthread_mutex_unlock libpthread-2.12.so 1.553 __audit_syscall_exit vmlinux 1.192 system_call vmlinux 1.156 erts_thr_yield beam.smp 1.114 handle_delayed_dealloc beam.smp 0.977 update beam.smp 0.828 raw_local_irq_enable vmlinux 0.780
可以看到sched_spin_wait占用了 40% 的CPU时间
#define ERTS_SCHED_SPIN_UNTIL_YIELD 100
2121 static erts_aint32_t
2122 sched_spin_wait(ErtsSchedulerSleepInfo *ssi, int spincount)
2123 {
2124 int until_yield = ERTS_SCHED_SPIN_UNTIL_YIELD;
2125 int sc = spincount;
2126 erts_aint32_t flgs;
2127
2128 do {
2129 flgs = erts_smp_atomic32_read_acqb(&ssi->flags);
2130 if ((flgs & (ERTS_SSI_FLG_SLEEPING|ERTS_SSI_FLG_WAITING))
2131 != (ERTS_SSI_FLG_SLEEPING|ERTS_SSI_FLG_WAITING)) {
2132 break;
2133 }
2134 ERTS_SPIN_BODY;
2135 if (--until_yield == 0) {
2136 until_yield = ERTS_SCHED_SPIN_UNTIL_YIELD;
2137 erts_thr_yield();
2138 }
2139 } while (--sc > 0);
2140 return flgs;
2141 }
默认spincount = 10000,但每次都有atom 读操作,原子操作一般几十到几百CPU周期,导致这个忙等待 实际执行完的话会很长。
同时也找到对应的配置:
+sbwt none|very_short|short|medium|long|very_longSet scheduler busy wait threshold. Default is medium. The threshold determines how long schedulers should busy wait when running out of work before going to sleep.
启动参数:+sbwt none 即可见spin彻底关掉,而不必像whatsapp patch beam解决。
同时strace 系统调用比较:
利用率高机器:
|
1
2
3
4
5
6
7
8
9
10
11
|
% time seconds usecs/call calls errors syscall------ ----------- ----------- --------- --------- ---------------- 34.07 0.022954 0 49747 writev 33.15 0.022336 0 58925 11806 recvfrom 21.04 0.014176 1 14558 2394 futex 8.37 0.005636 0 24722 4 epoll_ctl 2.71 0.001828 0 6947 epoll_wait 0.30 0.000199 10 19 munmap 0.24 0.000164 0 612 sched_yield 0.12 0.000078 16 5 mmap 0.00 0.000000 0 4 close |
利用率低机器:
% time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 86.38 13.138511 307 42838 7218 futex 6.91 1.050431 12 90659 writev 5.70 0.866909 13 69221 25351 recvfrom 0.54 0.082772 9 9307 sched_yield 0.43 0.065219 1 50157 epoll_ctl 0.01 0.002220 34 66 munmap 0.01 0.001092 1 815 epoll_wait 0.00 0.000675 20 34 mmap 0.00 0.000612 19 32 32 connect 0.00 0.000564 9 64 fcntl 0.00 0.000529 17 32 getsockname 0.00 0.000457 14 32 getsockopt 0.00 0.000341 11 32 socket 0.00 0.000127 16 8 read 0.00 0.000109 3 32 bind
两次strace 时间不同,可通过writev比例看出,第二次futex量要快高一倍,调度器线程切换较为严重