上篇文章我们介绍了utf8和utf8mb4的区别,这篇文章我们主要介绍utf8升级utf8mb4的步骤
utf8升级utf8mb4具体步骤:首先将我们数据库默认字符集由utf8更改为utf8mb4,然后将表默认字符集也更改为utf8mb4,最后再把存储表情的字段默认字符集也做相应的调整。
SQL 语句
# 修改数据库
> ALTER DATABASE database_name CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;
# 修改表
> ALTER TABLE table_name CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
# 修改表字段
> ALTER TABLE table_name CHANGE column_name column_name VARCHAR(191) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;修改MySQL配置文件,新增如下参数:
default-character-set = utf8mb4
default-character-set = utf8mb4
character-set-client-handshake = FALSE
character-set-server = utf8mb4
collation-server = utf8mb4_unicode_ci
init_connect='SET NAMES utf8mb4'解释:
– character_set_server:默认的内部操作字符集
– character_set_client:客户端来源数据使用的字符集
– character_set_connection:连接层字符集
– character_set_results:查询结果字符集
– character_set_database:当前选中数据库的默认字符集
– character_set_system:系统元数据(字段名等)字符集
– 还有以collation_开头的同上面对应的变量,用来描述字符序。
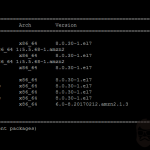
检查环境变量 和测试 SQL 如下:
SHOW VARIABLES WHERE Variable_name LIKE 'character\_set\_%' OR Variable_name LIKE'collation%';
注意:MySQL版本必须为5.5.3以上版本,否则不支持字符集utf8mb4

建议:
- 建议普通表使用utf8, 如果这个表需要支持emoji就使用utf8mb4
- 新建mysql库或者表的时候还有一个排序规则
- utf8_unicode_ci比较准确,utf8_general_ci速度比较快。通常情况下 utf8_general_ci的准确性就够我们用的了,在我看过很多程序源码后,发现它们大多数也用的是utf8_general_ci,所以新建数据 库时一般选用utf8_general_ci就可以了
- 如果是utf8mb4那么对应的就是 utf8mb4_general_ci utf8mb4_unicode_ci
utf8_unicode_ci与utf8_general_ci的区别
当前,utf8_unicode_ci校对规则仅部分支持Unicode校对规则算法。一些字符还是不能支持。并且,不能完全支持组合的记号。这主要影响越南和俄罗斯的一些少数民族语言,如:Udmurt 、Tatar、Bashkir和Mari。
utf8_unicode_ci的最主要的特色是支持扩展,即当把一个字母看作与其它字母组合相等时。例如,在德语和一些其它语言中‘ß’等于‘ss’
utf8_general_ci是一个遗留的校对规则,不支持扩展。它仅能够在字符之间进行逐个比较。这意味着utf8_general_ci校对规则进行的比较速度很快,但是与使用utf8_unicode_ci的校对规则相比,比较正确性较差
例如,使用utf8_general_ci和utf8_unicode_ci两种 校对规则下面的比较相等:
Ä = A
Ö = O
Ü = U
两种校对规则之间的区别是,对于utf8_general_ci下面的等式成立:ß = s
但是,对于utf8_unicode_ci下面等式成立:ß = ss
对于一种语言仅当使用utf8_unicode_ci排序做的不好时,才执行与具体语言相关的utf8字符集 校对规则。例如,对于德语和法语,utf8_unicode_ci工作的很好,因此不再需要为这两种语言创建特殊的utf8校对规则。
utf8_general_ci也适用与德语和法语,除了‘ß’等于‘s’,而不是‘ss’之外。如果你的应用能够接受这些,那么应该使用utf8_general_ci,因为它速度快。否则,使用utf8_unicode_ci,因为它比较准确。
案例
sql语句
CREATE TABLE test_session (
sessionId varchar(255) NOT NULL,
userId int(10) unsigned DEFAULT NULL,
createAt datetime DEFAULT NULL
)执行上面的代码会报一个错误:Specified key was too long; max key length is 767 bytes
当使用utf8mb4编码后,主键id的长度设置255,太长,只能设置小于191的
报错原因:utf8编码下,255长度的varchar长度约767,更改成utf8mb4后,最大只能支持191长度
max key length is 767 bytes
utf8: 767/3=255.6666666666667
utf8mb4: 767/4=191.75


![MYSQL[快问快答系列面试题]](https://blog.p2hp.com/wp-content/plugins/wordpress-23-related-posts-plugin/static/thumbs/12.jpg)