几乎你们每个人都必须编写一个程序,编译它然后运行它以查看你辛苦劳动的成果。终于看到你的程序正常工作感觉很好,不是吗?但为了使所有这些工作,我们还有其他人也要感恩。这就是你的编译器(当然,假设你使用的是编译语言,而不是解释的语言),这也在幕后做了很多努力。
在本文中,我将尝试向您展示您编写的源代码如何转换为您的机器实际上能够运行的内容。我选择Linux作为主机,C作为编程语言,但这里的概念足以应用于许多编译语言。
注意:如果您想在本文中进行操作,那么您必须确保在本地计算机上安装了gcc,elfutils。
让我们从一个简单的C程序开始,看看它是如何被编译器转换的。
#include <stdio.h>
// Main function
int main(void) {
int a = 1;
int b = 2;
int c = a + b;
printf("%d\n", c);
return 0;
}
该程序创建两个变量,将它们相加并在屏幕上打印结果。很简单,对吧?
但是,让我们看看这个看似简单的程序必须经历什么才能最终在您的系统上执行。
编译器通常有以下五个步骤(最后一步是操作系统的一部分) -

让我们详细介绍每个步骤。

第一步是预处理步骤,由预处理器完成。预处理器的工作是处理代码中存在的所有预处理器指令。这些指令以#开头。但在处理它们之前,它首先会从代码中删除所有注释,因为注释仅用于人类可读性。然后它找到所有#命令,并执行命令所说的内容。
在上面的代码中,我们刚刚使用了#include指令,它简单地告诉Preprocesssor复制stdio.h文件并将其粘贴到当前位置的此文件中。
您可以通过将-E标志传递给gcc编译器来查看预处理器的输出。
gcc -E sample.c你会得到类似以下的东西 -
# 1 "sample.c"
# 1 "<built-in>"
# 1 "<command-line>"
# 1 "/usr/include/stdc-predef.h" 1 3 4
# 1 "<command-line>" 2
# 1 "sample.c"
# 1 "/usr/include/stdio.h" 1 3 4
-----omitted-----
# 5 "sample.c"
int main(void) {
int a = 1;
int b = 2;
int c = a + b;
printf("%d\n", c);
return 0;
}

令人困惑的是,第二步也称为编译。编译器从预处理器获取输出,并负责执行以下重要任务。
- 通过词法分析器传递输出,以识别文件中存在的各种令牌。标记只是程序中存在的文字,如'int','return','void','0'等等。词法分析器还将每个标记与令牌的类型相关联,无论令牌是字符串文字,整数,浮点数,是否令牌等等。
- 将词法分析器的输出传递给语法分析器,检查程序是否以满足编写程序语言的语法规则的方式编写。例如,在解析这行代码时会引发语法错误,
b = a + ;因为+是一个缺少的操作数。
- 将语法分析器的输出传递给语义分析器,语义分析器检查程序是否满足语言的语义,如类型检查和变量在首次使用之前声明等。
- 如果程序在语法上是正确的,那么源代码将转换为指定目标体系结构的程序集说明。默认情况下,它为正在运行的计算机生成程序集。但是假设您正在为嵌入式系统构建程序,那么您可以通过目标机器的架构,gcc将为该机器生成程序集。
要查看此阶段的输出,请将-S标志传递给gcc编译器。
gcc -S sample.c根据您的环境,您将获得以下内容。
.file "sample.c" // name of the source file
.section .rodata // Read only data
.LC0: // Local constant
.string "%d\n" // string constant we used
.text // beginning of the code segment
.globl main // declare main symbol to be global
.type main, @function // main is a function
main: // beginning of main function
.LFB0: // Local function beginning
.cfi_startproc // ignore them
pushq %rbp // save the caller's frame pointer
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp // set the current stack pointer as the frame base pointer
.cfi_def_cfa_register 6
subq $16, %rsp // set up the space
movl $1, -12(%rbp)
movl $2, -8(%rbp)
movl -12(%rbp), %edx
movl -8(%rbp), %eax
addl %edx, %eax
movl %eax, -4(%rbp)
movl -4(%rbp), %eax
movl %eax, %esi
movl $.LC0, %edi
movl $0, %eax
call printf
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret // return from the function
.cfi_endproc
.LFE0:
.size main, .-main // size of the main function
.ident "GCC: (Ubuntu 5.4.0-6ubuntu1~16.04.4) 5.4.0 20160609"
.section .note.GNU-stack,"",@progbits // make stack non-executable
如果你不懂汇编语言,那一开始看起来都很可怕,但并不是那么糟糕。理解汇编代码需要比普通高级语言代码更多的时间,但是如果有足够的时间,你肯定可以阅读它。
我们来看看这个文件包含的内容。
所有以“。”开头的行 是汇编程序指令。.file表示源文件的名称,可用于调试目的。源代码%d \ n中的字符串文字现在位于.rodata部分(ro表示只读),因为它是一个只读字符串。编译器将此字符串命名为LC0,以便稍后在代码中引用它。每当您看到以.L开头的标签时,就意味着这些标签是当前文件的本地标签,对其他文件不可见。
.globl告诉main是一个全局符号,这意味着main可以从其他文件中调用。.type告诉main是一个函数。然后按照主要功能的组件进行操作。您可以忽略以cfi开头的指令。它们用于在异常情况下调用堆栈展开。我们将在本文中忽略它们,但您可以在此处了解更多相关信息。
让我们试着理解主函数的反汇编。
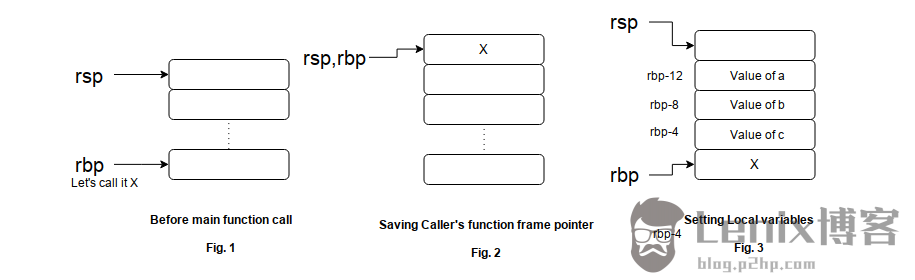
11。您必须知道,当您调用函数时,会为该函数创建一个新的堆栈框架。为了实现这一点,我们需要一些方法来知道新函数返回时调用者的函数帧指针的开始。这就是我们将存储在rbp寄存器中的当前帧指针压入堆栈的原因。
14将当前堆栈指针移动到基指针中。这成为我们当前的功能帧指针。图1描述了推动rbp寄存器之前的状态,图2显示了在前一帧指针被按下并且堆栈指针移动到当前帧指针之后。
16我们的程序中有3个局部变量,所有类型都是int。在我的机器上,每个int占用4个字节,因此我们需要12个字节的空间来保存我们的局部变量。我们在堆栈上为局部变量创建空间的方式是将堆栈指针递减我们局部变量所需的字节数。减少,因为堆栈从较高地址增长到较低地址。但是在这里你看到我们减少了16而不是12.原因是,空间被分配在16个字节的块中。因此,即使您有1个局部变量,也会在堆栈上分配16个字节的空间。这是出于某些架构的性能原因而完成的。请参见图3,了解堆栈现在的布局。
17-22这段代码很简单。编译器使用插槽rbp-12作为变量a的存储,rbp-8用于b,rbp-4用于c。它将值1和2 分别移动到变量a和b的地址。为准备添加,它将b值移至edx寄存器,并将a寄存器的值移至eax寄存器。添加的结果存储在eax寄存器中,该寄存器稍后被传送到c变量的地址。
23-27然后我们准备打印电话。首先,将c变量的值移动到esi寄存器。然后我们的字符串常量%d \ n的地址被移动到edi寄存器。esi和edi寄存器现在保存了printf调用的参数。edi持有第一个参数,esi持有第二个参数。然后我们调用printf函数来打印格式为整数值的变量c的值。这里要注意的是此时printf符号未定义。我们会看到这个printf 符号将在本文稍后解决。
.size以字节为单位表示main函数的大小。“ 。-main ”是一个表达式。symbol表示当前行的地址。所以这个表达式求值为current_address_of行 - 主函数的地址,它给出了主函数的大小,以字节为单位。
.ident告诉汇编器在.comment部分添加以下行。 .note.GNU-stack用于判断该程序的堆栈是否可执行。大多数情况下,该指令的值为空字符串,它告诉堆栈不可执行。

我们现在所拥有的是汇编语言中的程序,但它仍处于处理器无法理解的语言中。我们必须将汇编语言转换为机器语言,这项工作由汇编程序完成。汇编程序获取汇编文件并生成一个目标文件,该文件是包含程序机器指令的二进制文件。
让我们将汇编文件转换为目标文件,以查看正在运行的流程。要获取程序的目标文件,请将c标志传递给gcc编译器。
gcc -c sample.c你会得到一个扩展名为.o的目标文件。因为,这是一个二进制文件,您将无法在普通文本编辑器中打开它来查看它的内容。但是我们可以使用工具来查找这些目标文件中的内容。
对象文件可以有许多不同的文件格式。我们将专注于在Linux上使用的一个特别是ELF文件格式。
ELF文件包含以下信息 -
- ELF标题
- 程序头表
- 节头表
- 前几个表中提到的其他一些数据
ELF标头包含有关目标文件的一些元信息,例如文件类型,制作二进制文件的机器,版本,标头大小等。要查看标头,只需将-h标志传递给eu-readelf实用程序。
$ eu-readelf -h sample.o ELF Header: Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 Class: ELF64 Data: 2's complement, little endian Ident Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 Type: REL (Relocatable file) Machine: AMD x86-64 Version: 1 (current) Entry point address: 0 Start of program headers: 0 (bytes into file) Start of section headers: 704 (bytes into file) Flags: Size of this header: 64 (bytes) Size of program header entries: 0 (bytes) Number of program headers entries: 0 Size of section header entries: 64 (bytes) Number of section headers entries: 13 Section header string table index: 10
从上面的列表中,我们看到该文件没有任何程序标题,这很好。程序标题仅存在于可执行文件和共享库中。当我们在下一步中链接文件时,我们将看到程序标题。
但我们确实有13个部分。让我们看看这些部分是什么。使用-S标志。
$ eu-readelf -S sample.o There are 13 section headers, starting at offset 0x2c0: Section Headers: [Nr] Name Type Addr Off Size ES Flags Lk Inf Al [ 0] NULL 0000000000000000 00000000 00000000 0 0 0 0 [ 1] .text PROGBITS 0000000000000000 00000040 0000003c 0 AX 0 0 1 [ 2] .rela.text RELA 0000000000000000 00000210 00000030 24 I 11 1 8 [ 3] .data PROGBITS 0000000000000000 0000007c 00000000 0 WA 0 0 1 [ 4] .bss NOBITS 0000000000000000 0000007c 00000000 0 WA 0 0 1 [ 5] .rodata PROGBITS 0000000000000000 0000007c 00000004 0 A 0 0 1 [ 6] .comment PROGBITS 0000000000000000 00000080 00000035 1 MS 0 0 1 [ 7] .note.GNU-stack PROGBITS 0000000000000000 000000b5 00000000 0 0 0 1 [ 8] .eh_frame PROGBITS 0000000000000000 000000b8 00000038 0 A 0 0 8 [ 9] .rela.eh_frame RELA 0000000000000000 00000240 00000018 24 I 11 8 8 [10] .shstrtab STRTAB 0000000000000000 00000258 00000061 0 0 0 1 [11] .symtab SYMTAB 0000000000000000 000000f0 00000108 24 12 9 8 [12] .strtab STRTAB 0000000000000000 000001f8 00000016 0 0 0 1
您无需了解上述所有列表。但实际上,对于每个部分,它列出了各种信息,例如部分的名称,部分的大小以及从文件开头开始的部分的偏移量。我们使用的重要部分如下 -
- 文本部分包含我们的机器代码
- rodata部分包含我们程序中的只读数据。它可能是您在程序中使用的常量或字符串文字。这里只包含%d \ n
- 数据部分包含我们程序的初始化数据。这里是空的,因为我们没有任何初始化数据
- bss部分与数据部分类似,但包含我们程序的未初始化数据。未经初始化的数据可以是一个声明为int arr [100]的数组,它将成为本节的一部分。关于bss部分的一点要注意的是,与其他部分占据空间而不是取决于它们的内容,bss部分只包含部分的大小而没有别的。原因是在加载时,所需要的只是我们需要在本节中分配的字节数。通过这种方式,我们减少了最终可执行文件的大小
- strtab部分列出了我们程序中包含的所有字符串
- symtab部分是符号表。它包含我们程序的所有符号(变量和函数名称)。
- rela.text部分是重定位部分。稍后会详细介绍。
您还可以查看这些部分的内容,只需将相应的部分编号传递给eu-readelf程序即可。您也可以使用objdump工具。它还可以为您提供某些部分的拆解。
让我们更详细地谈谈rela.text部分。记住我们在程序中使用的printf函数。现在,printf是我们自己没有定义的东西,它是C库的一部分。通常,当您编译C程序时,编译器将以某种方式编译它们,以便您调用的C函数不与可执行文件捆绑在一起,从而减少了最终可执行文件的大小。相反,一个表由所有这些符号组成,称为重定位表,后来由称为加载器的东西填充。我们稍后将讨论有关装载程序部分的更多信息,但是现在,重要的是如果你看看rela.text部分,你会发现那里列出的printf符号。让我们确认一下这里。
$ eu-readelf -r sample.o Relocation section [ 2] '.rela.text' for section [ 1] '.text' at offset 0x210 contains 2 entries: Offset Type Value Addend Name 0x0000000000000027 X86_64_32 000000000000000000 +0 .rodata 0x0000000000000031 X86_64_PC32 000000000000000000 -4 printf Relocation section [ 9] '.rela.eh_frame' for section [ 8] '.eh_frame' at offset 0x240 contains 1 entry: Offset Type Value Addend Name 0x0000000000000020 X86_64_PC32 000000000000000000 +0 .text
您可以忽略第二个重定位部分.rela.eh_frame。它与异常处理有关,这对我们来说并不是很感兴趣。让我们看看那里的第一部分。在那里我们可以看到两个条目,其中一个是我们的printf符号。此条目的含义是,此文件中使用的符号名称为printf但尚未定义,该符号位于此文件中,位于.text部分开头的偏移量0x31处。让我们检查.text部分中现在偏移量为0x31的内容。
$ eu-objdump -d -j .text sample.o
sample.o: elf64-elf_x86_64
Disassembly of section .text:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 83 ec 10 sub $0x10,%rsp
8: c7 45 f4 01 00 00 00 movl $0x1,-0xc(%rbp)
f: c7 45 f8 02 00 00 00 movl $0x2,-0x8(%rbp)
16: 8b 55 f4 mov -0xc(%rbp),%edx
19: 8b 45 f8 mov -0x8(%rbp),%eax
1c: 01 d0 add %edx,%eax
1e: 89 45 fc mov %eax,-0x4(%rbp)
21: 8b 45 fc mov -0x4(%rbp),%eax
24: 89 c6 mov %eax,%esi
26: bf 00 00 00 00 mov $0x0,%edi
2b: b8 00 00 00 00 mov $0x0,%eax
30: e8 00 00 00 00 callq 0x35 <<<<<< offset 0x31
35: b8 00 00 00 00 mov $0x0,%eax
3a: c9 leaveq
3b: c3 retq
在这里,您可以看到偏移量为0x30的调用指令。e8代表调用指令的操作码,后跟从偏移量0x31到0x34的4个字节,这应该对应于我们现在没有的printf函数实际地址,因此它们只是00。(稍后,我们将看到位置实际上并不包含printf地址,而是使用名为plt table的内容间接调用它。稍后我们将介绍此部分)

到目前为止我们所做的所有事情都在一个源文件上工作。但实际上,这种情况很少发生。在实际的生产代码中,您需要编译和创建可执行文件的数百个源代码文件。那么到目前为止我们遵循的步骤将如何比较?
那么,这些步骤都将保持不变。所有源代码文件都将单独进行预处理,编译,汇编,最后我们将获得单独的目标代码文件。
现在,每个源代码文件都不会被孤立地写入。它们必须具有一些函数,全局变量必须在某个文件中定义,并在其他文件的不同位置使用。
链接器的工作是收集所有目标文件,遍历每个目标文件并跟踪每个文件定义的符号以及它使用的符号。它可以在每个目标文件的符号表中找到所有这些信息。收集所有这些信息后,链接器会创建一个单个目标文件,将每个单个目标文件中的所有部分组合到相应的部分中,并重新定位所有可以解析的符号。
在我们的例子中,我们没有源文件的集合,我们只有一个文件,但由于我们使用C库中的printf函数,我们的源文件将通过动态链接到C库。现在让我们链接我们的程序并进一步调查输出。
gcc sample.c我不会在这里详细介绍,因为它也是我们上面看到的一个ELF文件,只有一些新的部分。这里需要注意的一点是,当我们看到从汇编程序中获取的目标文件时,我们看到的地址是相对的。但是在链接了所有文件后,我们已经非常了解所有部分,因此,如果您检查这些阶段的输出,它也包含绝对地址。
在此阶段,链接器已识别出我们程序中使用的所有符号,谁使用这些符号,以及谁定义了这些符号。链接器只是将符号定义的地址映射到符号的用法。但是在完成所有这些之后,仍然存在一些尚未解决的符号,其中一个是我们的printf符号。通常,这些符号是外部定义的变量或外部定义的函数。链接器还创建一个重定位表,与Assembler创建的重定位表一样,这些条目仍未解析。
在这一点上,你应该知道一件事。您从其他库中使用的函数和数据可以静态链接或动态链接。静态链接意味着这些库中的函数和数据将被复制并粘贴到您的可执行文件中。然而,如果您进行动态链接,那么这些函数和数据不会复制到您的可执行文件中,从而减少了最终的可执行文件大小。
对于具有dyamic链接功能的libray,库必须是共享库(所以文件)。通常,许多程序使用的公共库都是共享库,其中一个是我们的libc库。如此众多的程序使用libc,如果每个程序都开始静态链接它,那么在任何时候,都会有很多相同代码的副本占用你内存中的空间。拥有动态链接可以解决这个问题,并且在任何时候只有一个libc副本占用内存空间,所有程序都将从该共享库中引用。
为了使动态链接成为可能,链接器会创建另外两个部分,这些部分在汇编程序生成的目标代码中不存在。这些是.plt(过程链接表)和.got (全局偏移表)部分。当我们加载可执行文件时,我们将介绍这些部分,因为这些部分在我们实际加载可执行文件时很有用。

现在是时候实际运行我们的可执行文件了。
当您单击GUI中的文件或从命令行运行它时,将调用间接的execev系统调用。正是这个系统调用,内核开始在内存中加载可执行文件的工作。
请记住上面的程序标题表。这是非常有用的地方。
$ eu-readelf -l a.out Program Headers: Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align PHDR 0x000040 0x0000000000400040 0x0000000000400040 0x0001f8 0x0001f8 R E 0x8 INTERP 0x000238 0x0000000000400238 0x0000000000400238 0x00001c 0x00001c R 0x1 [Requesting program interpreter: /lib64/ld-linux-x86-64.so.2] LOAD 0x000000 0x0000000000400000 0x0000000000400000 0x000724 0x000724 R E 0x200000 LOAD 0x000e10 0x0000000000600e10 0x0000000000600e10 0x000228 0x000230 RW 0x200000 DYNAMIC 0x000e28 0x0000000000600e28 0x0000000000600e28 0x0001d0 0x0001d0 RW 0x8 NOTE 0x000254 0x0000000000400254 0x0000000000400254 0x000044 0x000044 R 0x4 GNU_EH_FRAME 0x0005f8 0x00000000004005f8 0x00000000004005f8 0x000034 0x000034 R 0x4 GNU_STACK 0x000000 0x0000000000000000 0x0000000000000000 0x000000 0x000000 RW 0x10 GNU_RELRO 0x000e10 0x0000000000600e10 0x0000000000600e10 0x0001f0 0x0001f0 R 0x1 Section to Segment mapping: Segment Sections... 00 01 [RO: .interp] 02 [RO: .interp .note.ABI-tag .note.gnu.build-id .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt .init .plt .plt.got .text .fini .rodata .eh_frame_hdr .eh_frame] 03 [RELRO: .init_array .fini_array .jcr .dynamic .got] .got.plt .data .bss 04 [RELRO: .dynamic] 05 [RO: .note.ABI-tag .note.gnu.build-id] 06 [RO: .eh_frame_hdr] 07 08 [RELRO: .init_array .fini_array .jcr .dynamic .got]
内核如何知道在文件中找到该表的位置?那么,该信息可以在ELF标题中找到,它总是从文件中的偏移0开始。完成后,内核会查找所有LOAD类型的条目,并将它们加载到进程的内存空间中。
从上面的清单中可以看出,有两个类型为LOAD的条目。您还可以查看每个细分中包含哪些部分。
现代操作系统和处理器根据页面管理内存。您的计算机内存分为固定大小的块,当任何进程请求某些内存时,操作系统会为该进程分配一些页面。除了有效管理内存的好处之外,这还具有提供安全性的好处。操作系统和内核可以为每个页面设置保护位。保护位指定特定页面是否为只读,可以写入还是可以执行。保护位设置为只读的页面无法修改,因此可防止有意或无意地修改数据。
只读页面还有一个好处,即同一程序的多个运行进程可以共享相同的页面。由于页面是只读的,因此没有正在运行的进程可以修改这些页面,因此,每个进程都可以正常工作。
为了设置这些保护位,我们不得不告诉内核,哪些页面必须标记为只读,哪些页面可以写入和执行。这些信息存储在上面每个条目的Flags中。
注意第一个LOAD条目。它被标记为R和E,这意味着这些段可以被读取和执行但不能被修改,如果你向下看并看到哪些段落在这些段中,你可以看到两个熟悉的部分,。text和。罗达塔。因此,我们的代码和只读数据只能被读取和执行,但不能被修改,这是应该发生的事情。
类似地,第二个LOAD条目包含初始化和未初始化的数据,GOT表(后面将详细介绍),它们被标记为RW,因此可以读取和写入但不能执行。
加载这些段并设置其权限后,内核会检查是否存在.interp段。在静态链接的可执行文件中,不需要此段,因为可执行文件包含它需要的所有代码,但对于动态链接的可执行文件,此段很重要。该段包含.interp部分,其中包含动态链接器的路径。(通过将-static标志传递给gcc编译器并检查生成的可执行文件中的头表,可以检查静态链接的可执行文件中没有.interp段)
在我们的例子中,它会找到一个并指向此路径上的动态链接器/lib64/ld-linux-x86-64.so.2。与我们的可执行文件类似,内核将通过读取标头,查找其段并将它们加载到当前程序的内存空间来开始加载这些共享对象。在静态链接的可执行文件中,所有这些都不需要,内核可以控制我们的程序,这里内核控制动态链接器并推送我们的主函数的地址在堆栈上调用,以便在动态链接器之后完成它的工作,它知道将控制权交给哪里。
我们现在应该理解我们现在已经跳过太久的两个表,过程链接表和全局偏移表因为它们与动态链接器的功能密切相关。
您的程序可能需要两种类型的重定位。变量重定位和函数重定位。对于外部定义的变量,我们在GOT表中包含该条目,并且在外部定义的函数中包括这两个表中的条目。因此,从本质上讲,GOT表包含所有外部定义的变量和函数的条目,PLT表只有函数的条目。我们有两个函数条目的原因将通过以下示例清楚。
让我们举一个printf函数的例子来看看这些表是如何工作的。在我们的main函数中,让我们看一下printf函数的调用指令。
400556: e8 a5 fe ff ff callq 0x400400此调用指令调用的地址是.plt部分的一部分。让我们看看那里有什么。
$ objdump -d -j .plt a.out a.out: file format elf64-x86-64 Disassembly of section .plt: 00000000004003f0 <printf@plt-0x10>: 4003f0: ff 35 12 0c 20 00 pushq 0x200c12(%rip) # 601008 <_GLOBAL_OFFSET_TABLE_+0x8> 4003f6: ff 25 14 0c 20 00 jmpq *0x200c14(%rip) # 601010 <_GLOBAL_OFFSET_TABLE_+0x10> 4003fc: 0f 1f 40 00 nopl 0x0(%rax) 0000000000400400 <printf@plt>: 400400: ff 25 12 0c 20 00 jmpq *0x200c12(%rip) # 601018 <_GLOBAL_OFFSET_TABLE_+0x18> 400406: 68 00 00 00 00 pushq $0x0 40040b: e9 e0 ff ff ff jmpq 4003f0 <_init+0x28> 0000000000400410 <__libc_start_main@plt>: 400410: ff 25 0a 0c 20 00 jmpq *0x200c0a(%rip) # 601020 <_GLOBAL_OFFSET_TABLE_+0x20> 400416: 68 01 00 00 00 pushq $0x1 40041b: e9 d0 ff ff ff jmpq 4003f0 <_init+0x28>
对于每个外部定义的函数,我们在plt部分中有一个条目,除了第一个条目外,它们看起来都相同并且有三条指令。这是一个特殊条目,我们将在稍后看到它的使用。
在那里我们发现跳转到地址0x601018所包含的值。这些地址是GOT表中的一个条目。我们来看看这些地址的内容。
$ objdump -s a.out | grep -A 3 '.got.plt' Contents of section .got.plt: 601000 280e6000 00000000 00000000 00000000 (.`............. 601010 00000000 00000000 06044000 00000000 ..........@..... 601020 16044000 00000000 ..@.....
这就是魔术发生的地方。除了第一次调用printf函数时,此地址的值将是来自C库的printf函数的实际地址,我们只需跳转到该位置即可。但这是第一次发生其他事情。
当第一次调用printf函数时,此位置的值是printf函数的plt条目中下一条指令的地址。从上面的清单中可以看出,它是400406,以小端格式存储。在plt条目的这个位置,我们有一个push指令,它将0推入堆栈。每个plt条目都有相同的推送指令,但它们推送不同的数字。0这里表示重定位表中printf符号的偏移量。然后,按下指令后跟跳转指令,跳转指令跳转到第一个plt条目中的第一条指令。
请记住,当我告诉你第一个条目是特殊的时候。这是因为在这里调用动态链接器来解析外部符号并重新定位它们。为此,我们跳转到got表中地址601010中包含的地址。这些地址应包含处理重定位的动态链接器例程的地址。现在这些条目填充为0,但是当程序实际运行并且内核调用动态链接器时,链接器会填充此地址。
调用例程时,链接器将从外部共享对象解析先前推送的符号(在我们的示例中为0),并将符号的正确地址放在got表中。所以,从现在开始,当调用printf函数时,我们不必查阅链接器,我们可以直接从plt跳转到C库中的printf函数。
此过程称为延迟加载。程序可能包含许多外部符号,但在程序的一次运行中可能不会调用它们。因此,符号解析延迟到实际使用,这节省了一些程序启动时间。
从上面的讨论中可以看出,我们从来没有必要修改plt部分,而只修改了部分。这就是为什么plt部分位于第一个LOAD段并标记为只读,而got部分位于第二个LOAD段并标记为Write。
这就是动态链接器的工作原理。我已经跳过了很多血腥的细节,但如果你有兴趣了解更多细节,那么你可以查看这篇文章。
让我们回到我们的程序加载。我们已经完成了大部分工作。内核已加载所有可加载的段,已调用动态链接器。剩下的就是调用我们的主要功能。并且该工作在链接器完成后由链接器完成。当它调用我们的主函数时,我们在终端中得到以下输出 -
3我的朋友,幸福。
感谢您阅读我的文章。如果你喜欢我的文章或任何其他建议,请在下面的评论部分告诉我。请随便分享:)
原创翻译,转载请注明来自Lenix的博客,地址https://blog.p2hp.com/archives/6310