有一段时间没怎么写文章了,今天提笔写一篇自己对 API 设计的思考。首先,为什么写这个话题呢?其一,我阅读了《阿里研究员谷朴:API 设计最佳实践的思考》一文后受益良多,前两天并转载了这篇文章也引发了广大读者的兴趣,我觉得我应该把我自己的思考整理成文与大家一起分享与碰撞。其二,我觉得我针对这个话题,可以半个小时之内搞定,争取在 1 点前关灯睡觉,哈哈。
现在,我们来一起探讨 API 的设计之道。我会抛出几个观点,欢迎探讨。
一、定义好的规范,已经成功了一大半
通常情况下,规范就是大家约定俗成的标准,如果大家都遵守这套标准,那么自然沟通成本大大降低。例如,大家都希望从阿里的规范上面学习,在自己的业务中也定义几个领域模型:VO、BO、DO、DTO。其中,DO(Data Object)与数据库表结构一一对应,通过 DAO 层向上传输数据源对象。 而 DTO(Data Transfer Object)是远程调用对象,它是 RPC 服务提供的领域模型。对于 BO(Business Object),它是业务逻辑层封装业务逻辑的对象,一般情况下,它是聚合了多个数据源的复合对象。那么,VO(View Object) 通常是请求处理层传输的对象,它通过 Spring 框架的转换后,往往是一个 JSON 对象。
事实上,阿里这种复杂的业务中如果不划分清楚 DO、BO、DTO、VO 的领域模型,其内部代码很容易就混乱了,内部的 RPC 在 service 层的基础上又增加了 manager 层,从而实现内部的规范统一化。但是,如果只是单独的域又没有太多外部依赖,那么,完全不要设计这么复杂,除非预期到可能会变得庞大和复杂化。对此,设计过程中因地制宜就显得特别重要了。
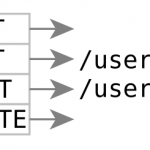
另外一个规范的例子是 RESTful API。在 REST 架构风格中,每一个 URI 代表一种资源。因此,URI 是每一个资源的地址的唯一资源定位符。所谓资源,实际上就是一个信息实体,它可以是服务器上的一段文本、一个文件、一张图片、一首歌曲,或者是一种服务。RESTful API 规定了通过 GET、 POST、 PUT、 PATCH、 DELETE 等方式对服务端的资源进行操作。
- 【GET】 /users # 查询用户信息列表
- 【GET】 /users/1001 # 查看某个用户信息
- 【POST】 /users # 新建用户信息
- 【PUT】 /users/1001 # 更新用户信息(全部字段)
- 【PATCH】 /users/1001 # 更新用户信息(部分字段)
- 【DELETE】 /users/1001 # 删除用户信息
事实上,RESTful API 的实现分了四个层级。第一层次(Level 0)的 Web API 服务只是使用 HTTP 作为传输方式。第二层次(Level 1)的 Web API 服务引入了资源的概念。每个资源有对应的标识符和表达。第三层次(Level 2)的 Web API 服务使用不同的 HTTP 方法来进行不同的操作,并且使用 HTTP 状态码来表示不同的结果。第四层次(Level 3)的 Web API 服务使用 HATEOAS。在资源的表达中包含了链接信息。客户端可以根据链接来发现可以执行的动作。通常情况下,伪 RESTful API 都是基于第一层次与第二层次设计的。例如,我们的 Web API 中使用各种动词,例如 get_menu 和 save_menu ,而真正意义上的 RESTful API 需要满足第三层级以上。如果我们遵守了这套规范,我们就很可能就设计出通俗易懂的 API。
注意的是,定义好的规范,我们已经成功了一大半。如果这套规范是业内标准,那么我们可以大胆实践,不要担心别人不会用,只要把业界标准丢给他好好学习一下就可以啦。例如,Spring 已经在 Java 的生态中举足轻重,如果一个新人不懂 Spring 就有点说不过去了。但是,很多时候因为业务的限制和公司的技术,我们可能使用基于第一层次与第二层次设计的伪 RESTful API,但是它不一定就是落后的,不好的,只要团队内部形成规范,降低大家的学习成本即可。很多时候,我们试图改变团队的习惯去学习一个新的规范,所带来的收益(投入产出比)甚微,那就得不偿失了。
总结一下,定义好的规范的目的在于,降低学习成本,使得 API 尽可能通俗易懂。当然,设计的 API 通俗易懂还有其他方式,例如我们定义的 API 的名字易于理解,API 的实现尽可能通用等。
二、探讨 API 接口的兼容性
API 接口都是不断演进的。因此,我们需要在一定程度上适应变化。在 RESTful API 中,API 接口应该尽量兼容之前的版本。但是,在实际业务开发场景中,可能随着业务需求的不断迭代,现有的 API 接口无法支持旧版本的适配,此时如果强制升级服务端的 API 接口将导致客户端旧有功能出现故障。实际上,Web 端是部署在服务器,因此它可以很容易为了适配服务端的新的 API 接口进行版本升级,然而像 Android 端、IOS 端、PC 端等其他客户端是运行在用户的机器上,因此当前产品很难做到适配新的服务端的 API 接口,从而出现功能故障,这种情况下,用户必须升级产品到最新的版本才能正常使用。为了解决这个版本不兼容问题,在设计 RESTful API 的一种实用的做法是使用版本号。一般情况下,我们会在 url 中保留版本号,并同时兼容多个版本。
- 【GET】 /v1/users/{user_id} // 版本 v1 的查询用户列表的 API 接口
- 【GET】 /v2/users/{user_id} // 版本 v2 的查询用户列表的 API 接口
现在,我们可以不改变版本 v1 的查询用户列表的 API 接口的情况下,新增版本 v2 的查询用户列表的 API 接口以满足新的业务需求,此时,客户端的产品的新功能将请求新的服务端的 API 接口地址。虽然服务端会同时兼容多个版本,但是同时维护太多版本对于服务端而言是个不小的负担,因为服务端要维护多套代码。这种情况下,常见的做法不是维护所有的兼容版本,而是只维护最新的几个兼容版本,例如维护最新的三个兼容版本。在一段时间后,当绝大多数用户升级到较新的版本后,废弃一些使用量较少的服务端的老版本API 接口版本,并要求使用产品的非常旧的版本的用户强制升级。注意的是,“不改变版本 v1 的查询用户列表的 API 接口”主要指的是对于客户端的调用者而言它看起来是没有改变。而实际上,如果业务变化太大,服务端的开发人员需要对旧版本的 API 接口使用适配器模式将请求适配到新的API 接口上。
有趣的是,GraphQL 提供不同的思路。GraphQL 为了解决服务 API 接口爆炸的问题,以及将多个 HTTP 请求聚合成了一个请求,提出只暴露单个服务 API 接口,并且在单个请求中可以进行多个查询。GraphQL 定义了 API 接口,我们可以在前端更加灵活调用,例如,我们可以根据不同的业务选择并加载需要渲染的字段。因此,服务端提供的全量字段,前端可以按需获取。GraphQL 可以通过增加新类型和基于这些类型的新字段添加新功能,而不会造成兼容性问题。
此外,在使用 RPC API 过程中,我们特别需要注意兼容性问题,二方库不能依赖 parent,此外,本地开发可以使用 SNAPSHOT,而线上环境禁止使用,避免发生变更,导致版本不兼容问题。我们需要为每个接口都应定义版本号,保证后续不兼容的情况下可以升级版本。例如,Dubbo 建议第三位版本号通常表示兼容升级,只有不兼容时才需要变更服务版本。
关于规范的案例,我们可以看看 k8s 和 github,其中 k8s 采用了 RESTful API,而 github 部分采用了 GraphQL。
- https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.10/
- https://developer.github.com/v4/
三、提供清晰的思维模型
所谓思维模型,我的理解是针对问题域抽象模型,对域模型的功能有统一认知,构建某个问题的现实映射,并划分好模型的边界,而域模型的价值之一就是统一思想,明确边界。假设,大家没有清晰的思维模型,那么也不存在对 API 的统一认知,那么就很可能出现下面图片中的现实问题。
四、以抽象的方式屏蔽业务实现
我认为好的 API 接口具有抽象性,因此需要尽可能的屏蔽业务实现。那么,问题来了,我们怎么理解抽象性?对此,我们可以思考 java.sql.Driver 的设计。这里,java.sql.Driver 是一个规范接口,而 com.mysql.jdbc.Driver
则是 mysql-connector-java-xxx.jar 对这个规范的实现接口。那么,切换成 Oracle 的成本就非常低了。
一般情况下,我们会通过 API 对外提供服务。这里,API 提供服务的接口的逻辑是固定的,换句话说,它具有通用性。但是,但我们遇到具有类似的业务逻辑的场景时,即核心的主干逻辑相同,而细节的实现略有不同,那我们该何去何从?很多时候,我们会选择提供多个 API 接口给不同的业务方使用。事实上,我们可以通过 SPI 扩展点来实现的更加优雅。什么是 SPI?SPI 的英文全称是 Serivce Provider Interface,即服务提供者接口,它是一种动态发现机制,可以在程序执行的过程中去动态的发现某个扩展点的实现类。因此,当 API 被调用时会动态加载并调用 SPI 的特定实现方法。
此时,你是不是联想到了模版方法模式。模板方法模式的核心思想是定义骨架,转移实现,换句话说,它通过定义一个流程的框架,而将一些步骤的具体实现延迟到子类中。事实上,在微服务的落地过程中,这种思想也给我们提供了非常好的理论基础。
现在,我们来看一个案例:电商业务场景中的未发货仅退款。这种情况在电商业务中非常场景,用户下单付款后由于各种原因可能就申请退款了。此时,因为不涉及退货,所以只需要用户申请退款并填写退款原因,然后让卖家审核退款。那么,由于不同平台的退款原因可能不同,我们可以考虑通过 SPI 扩展点来实现。
此外,我们还经常使用工厂方法+策略模式来屏蔽外部的复杂性。例如,我们对外暴露一个 API 接口 getTask(int operation),那么我们就可以通过工厂方法来创建实例,通过策略方法来定义不同的实现。
- @Component
- public class TaskManager {
- private static final Logger logger = LoggerFactory.getLogger(TaskManager.class);
- private static TaskManager instance;
- public MapInteger, ITask> taskMap = new HashMap<Integer, ITask>();
- public static TaskManager getInstance() {
- return instance;
- }
- public ITask getTask(int operation) {
- return taskMap.get(operation);
- }
- /**
- * 初始化处理过程
- */
- @PostConstruct
- private void init() {
- logger.info("init task manager");
- instance = new TaskManager();
- // 单聊消息任务
- instance.taskMap.put(EventEnum.CHAT_REQ.getValue(), new ChatTask());
- // 群聊消息任务
- instance.taskMap.put(EventEnum.GROUP_CHAT_REQ.getValue(), new GroupChatTask());
- // 心跳任务
- instance.taskMap.put(EventEnum.HEART_BEAT_REQ.getValue(), new HeatBeatTask());
- }
- }
还有一种屏蔽内部复杂性设计就是外观接口,它是将多个服务的接口进行业务封装与整合并提供一个简单的调用接口给客户端使用。这种设计的好处在于,客户端不再需要知道那么多服务的接口,只需要调用这个外观接口即可。但是,坏处也是显而易见的,即增加了服务端的业务复杂度,接口性能不高,并且复用性不高。因此,因地制宜,尽可能保证职责单一,而在客户端进行“乐高式”组装。如果存在 SEO 优化的产品,需要被类似于百度这样的搜索引擎收录,可以当首屏的时候,通过服务端渲染生成 HTML,使之让搜索引擎收录,若不是首屏的时候,可以通过客户端调用服务端 RESTful API 接口进行页面渲染。
此外,随着微服务的普及,我们的服务越来越多,许多较小的服务有更多的跨服务调用。因此,微服务体系结构使得这个问题更加普遍。为了解决这个问题,我们可以考虑引入一个“聚合服务”,它是一个组合服务,可以将多个微服务的数据进行组合。这样设计的好处在于,通过一个“聚合服务”将一些信息整合完后再返回给调用方。注意的是,“聚合服务”也可以有自己的缓存和数据库。 事实上,聚合服务的思想无处不在,例如 Serverless 架构。我们可以在实践的过程中采用 AWS Lambda 作为 Serverless 服务背后的计算引擎,而 AWS Lambda 是一种函数即服务(Function-as-a-Servcie,FaaS)的计算服务,我们直接编写运行在云上的函数。那么,这个函数可以组装现有能力做服务聚合。
当然,还有很多很好的设计,我也会在陆续在公众号中以续补的方式进行补充与探讨。
五、考虑背后的性能
我们需要考虑入参字段的各种组合导致数据库的性能问题。有的时候,我们可能暴露太多字段给外部组合使用,导致数据库没有相应的索引而发生全表扫描。事实上,这种情况在查询的场景特别常见。因此,我们可以只提供存在索引的字段组合给外部调用,或者在下面的案例中,要求调用方必填 taskId 和 caseId 来保证我们数据库合理使用索引,进一步保证服务提供方的服务性能。
- ResultVoid> agree(Long taskId, Long caseId, Configger configger);
同时,对于报表操作、批量操作、冷数据查询等 API 应该可以考虑异步能力。
此外,GraphQL 虽然解决将多个 HTTP 请求聚合成了一个请求,但是 schema 会逐层解析方式递归获取全部数据。例如分页查询的统计总条数,原本 1 次可以搞定的查询,演变成了 N + 1 次对数据库查询。此外,如果写得不合理还会导致恶劣的性能问题,因此,我们在设计的过程中特别需要注意。
六、异常响应与错误机制
业内对 RPC API 抛出异常,还是抛出错误码已经有太多的争论。《阿里巴巴 Java 开发手册》建议:跨应用 RPC 调用优先考虑使用 isSuccess() 方法、“错误码”、“错误简短信息”。关于 RPC 方法返回方式使用 Result 方式的理由 : 1)使用抛异常返回方式,调用方如果没有捕获到,就会产生运行时错误。2)如果不加栈信息,只是 new 自定义异常,加入自己的理解的 error message,对于调用端解决问题的帮助不会太多。如果加了栈信息,在频繁调用出错的情况下,数据序列化和传输的性能损耗也是问题。当然,我也支持这个论点的实践拥护者。
- public ResultXxxDTO> getXxx(String param) {
- try {
- // ...
- return Result.create(xxxDTO);
- } catch (BizException e) {
- log.error("...", e);
- return Result.createErrorResult(e.getErrorCode(), e.getErrorInfo(), true);
- }
- }
在 Web API 设计过程中,我们会使用 ControllerAdvice 统一包装错误信息。而在微服务复杂的链式调用中,我们会比单体架构更难以追踪与定位问题。因此,在设计的时候,需要特别注意。一种比较好的方案是,当 RESTful API 接口出现非 2xx 的 HTTP 错误码响应时,采用全局的异常结构响应信息。其中,code 字段用来表示某类错误的错误码,在微服务中应该加上“{biz_name}/”前缀以便于定位错误发生在哪个业务系统上。我们来看一个案例,假设“用户中心”某个接口没有权限获取资源而出现错误,我们的业务系统可以响应“UC/AUTH_DENIED”,并且通过自动生成的 UUID 值的 request_id 字段,在日志系统中获得错误的详细信息。
- HTTP/1.1 400 Bad Request
- Content-Type: application/json
- {
- "code": "INVALID_ARGUMENT",
- "message": "{error message}",
- "cause": "{cause message}",
- "request_id": "01234567-89ab-cdef-0123-456789abcdef",
- "host_id": "{server identity}",
- "server_time": "2014-01-01T12:00:00Z"
- }
七、思考 API 的幂等性
幂等机制的核心是保证资源唯一性,例如客户端重复提交或服务端的多次重试只会产生一份结果。支付场景、退款场景,涉及金钱的交易不能出现多次扣款等问题。事实上,查询接口用于获取资源,因为它只是查询数据而不会影响到资源的变化,因此不管调用多少次接口,资源都不会改变,所以是它是幂等的。而新增接口是非幂等的,因为调用接口多次,它都将会产生资源的变化。因此,我们需要在出现重复提交时进行幂等处理。那么,如何保证幂等机制呢?事实上,我们有很多实现方案。其中,一种方案就是常见的创建唯一索引。在数据库中针对我们需要约束的资源字段创建唯一索引,可以防止插入重复的数据。但是,遇到分库分表的情况是,唯一索引也就不那么好使了,此时,我们可以先查询一次数据库,然后判断是否约束的资源字段存在重复,没有的重复时再进行插入操作。注意的是,为了避免并发场景,我们可以通过锁机制,例如悲观锁与乐观锁保证数据的唯一性。这里,分布式锁是一种经常使用的方案,它通常情况下是一种悲观锁的实现。但是,很多人经常把悲观锁、乐观锁、分布式锁当作幂等机制的解决方案,这个是不正确的。除此之外,我们还可以引入状态机,通过状态机进行状态的约束以及状态跳转,确保同一个业务的流程化执行,从而实现数据幂等。事实上,并不是所有的接口都要保证幂等,换句话说,是否需要幂等机制可以通过考量需不需要确保资源唯一性,例如行为日志可以不考虑幂等性。当然,还有一种设计方案是接口不考虑幂等机制,而是在业务实现的时候通过业务层面来保证,例如允许存在多份数据,但是在业务处理的时候获取最新的版本进行处理。
via http://blog.720ui.com/2019/api_design_talk/