设计HTTP和RESTful API可能很棘手,因为没有官方和强制标准。基本上,有许多方法可以实现API,但其中一些已在实践中得到证实,并且已被widley采用。这篇文章介绍了构建HTTP和RESTful API的最佳实践。我们将讨论URL结构,HTTP方法,创建和更新资源,设计关系,有效负载格式,分页,版本控制等等。
更新2018年
我完全重写了这篇文章。我重新访问并扩展了现有的部分并添加了许多新的部分:HTTP方法和状态代码的新概述,PATCH,清除PUT和POST的语义,data字段,设计关系,REST与RPC风格的API,可演化性,版本控制方法,基于键集分页,JSON:API,JSON:API启发的有效负载格式。
每个资源使用两个URL
集合的一个URL和单个资源的一个URL:
# URL that represents a collection of resources
/employees
# URL that represents a single resource
/employees/56
使用一致的复数名词
比较喜欢
/employees
/employees/21
过度
/employee
/employee/21
实际上,这是一个品味问题,但复数形式更为常见。此外,它更直观,尤其是在集合URL上使用GET(GET /employee返回多个员工)时。但最重要的是:避免混合复数和单数名词,这是令人困惑和容易出错的。
使用名词而不是动词资源
这将使您的API简单并且URL数量较少。不要这样做:
/getAllEmployees
/getAllExternalEmployees
/createEmployee
/updateEmployee
相反,在一小组URL上使用可用的HTTP方法表达所需的操作。见下一节。
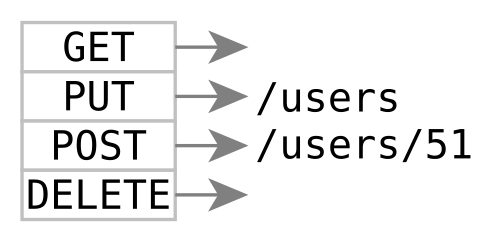
HTTP方法
使用HTTP方法对您的资源进行操作
GET /employees
GET /employees?state=external
POST /employees
PUT /employees/56
使用URL指定要使用的资源。使用HTTP方法指定如何处理此资源。使用五种HTTP方法GET,POST,PUT,PATCH和DELETE,您可以提供CRUD功能(创建,读取,更新,删除)等。
- 阅读:使用GET阅读资源。
- 创建:使用POST或PUT创建新资源。
- 更新:使用PUT和PATCH更新现有资源。
- 删除:使用DELETE删除现有资源。
理解HTTP方法的语义
Idempotence的定义:当我们可以安全地一遍又一遍地执行请求并且所有请求都导致相同的状态时,HTTP方法是幂等的。
- 得到
- 幂等
- 只读。GET 永远不会改变服务器端资源的状态。它必须没有副作用。
- 因此,可以安全地缓存响应。
- 例子:
GET /employees- 列出所有员工GET /employees/1- 显示员工1的详细信息
- 放
- 幂等!
- 可用于创建和更新
- 通常用于更新(完整更新)。
- 示例:
PUT /employees/1- 更新员工1(不常见:创建员工1)
- 示例:
- 要使用PUT进行创建,客户端需要预先知道整个URL(包括ID)。这种情况并不常见,因为服务器通常会生成ID。因此,当只有一个元素且URL明确无误时,通常会使用PUT进行创建。
- 示例:
PUT /employees/1/avatar- 创建或更新员工1的头像。每个员工只有一个头像。
- 示例:
- 始终在请求中包含整个有效负载。这是全有或全无。PUT不用于部分更新(请参阅PATCH)。
- POST
- 不是幂等的!
- 用于创建
- 示例:
POST /employees创建新员工。新URL将在Location标头中传送回客户端(例如Location: /employees/12)。多个POST请求/employees导致许多新的不同员工(这就是为什么POST不是幂等的)。
- 补丁
- 幂等
- 用于部分更新。
- 示例:
PATCH /employees/1- 使用有效负载中包含的字段更新员工1。员工1的其他字段不会更改。
- 删除
- 幂等
- 用于删除。
- 例:
DELETE /employees/1
在资源收集URL上POST以创建新资源
用于创建新资源的客户端 - 服务器交互怎么样?

- 客户端向资源集合URL发送POST请求
/employees。HTTP正文包含新资源“Paul”的属性。 - RESTful Web服务为新员工生成ID,在其内部模型中创建员工并向客户端发送响应。此响应包含状态代码201(已创建)和
LocationHTTP标头,该标头指示可在其下访问所创建资源的URL。
PUT在单个资源URL上更新资源

- 客户端向单个资源URL发送PUT请求
/employee/21。PUT请求的HTTP主体包含员工的所有字段,每个字段都将在服务器端更新。 - REST服务使用ID 21 更新员工
name和status员工,并使用HTTP状态代码200确认更改。
使用PATCH进行资源的部分更新
PUT 不应该用于部分更新。PUT应仅用于完全替换资源。每次发送所有字段(尽管您只想更新单个字段)可能会导致在并行更新时意外覆盖。此外,验证的实现很难,因为您必须支持两种用例:同时创建(某些字段不得null)和更新(null标记不应更新的字段的值)。因此,请勿使用PUT并仅发送应更新的字段。PUT请求中缺少的字段应被视为null值并清空数据库字段或触发验证错误。
而是使用PATCH进行部分更新。仅发送应更新的字段。这样,请求有效负载非常直接,不同字段的并行更新不会覆盖不相关的字段,验证变得更容易,null值的语义是明确的(对于PUT和PATCH)并且您节省了带宽。
例如,以下PATCH请求仅更新status字段,但不更新name。

实现旁注:除了描述的“只发送您想要更新的内容”方法(JSON:API也推荐)之外,还有JSON-PATCH。它是PATCH请求的有效负载格式,描述了应在资源上执行的一系列更改。但是,对于许多用例来说,实现和过度杀戮是很棘手的。有关更多详细信息,请查看帖子“ PUT vs PATCH vs JSON-PATCH”。
将实际数据包装在data字段中
GET /employees返回data字段中的对象列表:
{
"data": [
{ "id": 1, "name": "Larry" }
, { "id": 2, "name": "Peter" }
]
}
GET /employees/1返回data字段中的单个对象:
{
"data": {
"id": 1,
"name": "Larry"
}
}
PUT,POST和PATCH请求的有效负载还应包含data具有实际对象的字段。
好处:
- 还有空间来添加元数据(例如,用于分页,链接,弃用警告,错误消息)
- 一致性
- 与JSON:API标准兼容
对可选参数和复杂参数使用查询字符串(?)
不要这样做:
GET /employees
GET /externalEmployees
GET /internalEmployees
GET /internalAndSeniorEmployees
保持您的网址简单,并将网址设置得很小。为您的资源选择一个基本URL并坚持下去。将复杂性或可选参数移动到查询字符串。
GET /employees?state=internal&title=senior
GET /employees?id=1,2
JSON:API过滤方式是:
GET /employees?filter[state]=internal&filter[title]=senior
GET /employees?filter[id]=1,2
使用HTTP状态代码
RESTful Web服务应使用合适的HTTP状态响应代码响应客户端的请求。
2xx- 成功 - 一切都很好。4xx- 客户端错误 - 如果客户端出错了(例如客户端发送无效请求或未经授权)5xx- 服务器错误 - 服务器端的故障(尝试处理请求时的错误,如数据库故障,依赖服务不可用,编程错误或不应发生的状态)
考虑可用的HTTP状态代码。但请注意,使用所有这些内容可能会让您的API用户感到困惑。保持使用的HTTP状态代码集很小。通常使用以下代码:
- 2xx:成功
- 200好的
- 201创建
- 3xx:重定向
- 301永久移动
- 304未修改
- 4xx:客户端错误
- 400错误请求
- 401未经授权
- 403禁止
- 404未找到
- 410已经走了
- 5xx:服务器错误
- 500内部服务器错误
不要过度使用404。试着更精确。如果资源可用,但不允许用户查看它,则返回403 Forbidden。如果资源存在一次但现在已被删除或停用,请使用410 Gone。
提供有用的错误消息
除了适当的状态代码之外,您还应该在HTTP响应正文中提供有用且详细的错误描述。这是一个例子。
请求:
GET /employees?state=super
响应:
// 400 Bad Request
{
"errors": [
{
"status": 400,
"detail": "Invalid state. Valid values are 'internal' or 'external'",
"code": 352,
"links": {
"about": "http://www.domain.com/rest/errorcode/352"
}
}
]
}
建议的错误有效负载结构受JSON:API标准的启发。
提供浏览API的链接(HATEOAS)
理想情况下,您不要让客户构建使用REST API的URL。让我们考虑一个例子。
客户想要访问员工的工资报表。因此,他必须知道他可以通过将查询参数附加salaryStatements到员工URL(例如/employees/21/salaryStatements)来访问工资报表。这种字符串连接容易出错,易碎且难以维护。如果您更改了在REST API中访问salary语句的方式(例如,现在使用“salary-statements”或“paySlips”),则所有客户端都将中断。
最好在您的回复中提供客户可以遵循的链接。例如,响应GET /employees可能如下所示:
{
"data": [
{
"id":1,
"name":"Paul",
"links": [
{
"salary": "http://www.domain.com/employees/1/salaryStatements"
}
]
}
]
}
如果客户端完全依赖链接来获取工资声明,那么如果您更改API,他将不会中断,因为客户端将始终获得有效的URL(只要您在URL更改时更新链接)。另一个好处是,您的API变得更具自我描述性,客户端不必经常查找文档。
适当地设计关系
我们假设每个employee都有一个manager和几个teamMembers。在API中设计关系基本上有三种常用选项:链接,侧载和嵌入。
它们都是有效的,正确的选择取决于用例。基本上,您应该根据客户端的访问模式以及可容忍的请求数量和有效负载大小来设计关系。
链接
{
"data": [
{
"id": 1,
"name": "Larry",
"relationships": {
"manager": "http://www.domain.com/employees/1/manager",
"teamMembers": [
"http://www.domain.com/employees/12",
"http://www.domain.com/employees/13"
]
//or "teamMembers": "http://www.domain.com/employees/1/teamMembers"
}
}
]
}
- 有效负载小。如果客户不需要
manager和teamManager每次都很好,这很好。 - 许多请求。如果几乎每个客户都需要这些数据,这很糟糕。可能还需要许多其他请求; 在每个员工的最坏情况下。这是由每个关系(相乘
manager,teamMembers等等)的员工都有。 - 客户端必须将数据拼接在一起才能获得全局。
侧面加载
我们可以引用与外键的关系,并将引用的实体也放在有效载荷中但在专用字段下included。这种方法也称为“复合文件”。
{
"data": [
{
"id": 1,
"name": "Larry",
"relationships": {
"manager": 5 ,
"teamMembers": [ 12, 13 ]
}
}
],
"included": {
"manager": {
"id": 5,
"name": "Kevin"
},
"teamMembers": [
{ "id": 12, "name": "Albert" }
, { "id": 13, "name": "Tom" }
]
}
}
客户端还可以通过查询参数来控制侧载实体GET /employees?include=manager,teamMembers。
- 我们相处一个请求。
- 量身定制的有效载荷大小。没有重复(例如,即使他被许多员工引用,您也只能提供一次经理)
- 客户端仍然必须将数据拼接在一起以便解决关系,这可能非常麻烦。
嵌入
{
"data": [
{
"id": 1,
"name": "Larry",
"manager": {
"id": 5,
"name": "Kevin"
},
"teamMembers": [
{ "id": 12, "name": "Albert" }
, { "id": 13, "name": "Tom" }
]
}
]
}
- 对客户来说最方便。是可以直接跟随关系来获取实际数据。
- 如果客户端不需要关系,则可能无法加载关系。
- 增加有效负载大小和重复。可以多次嵌入引用的实体。
使用CamelCase作为属性名称
使用CamelCase作为属性标识符。
{ "yearOfBirth": 1982 }
不要使用下划线(year_of_birth)或大写(YearOfBirth)。通常,您的RESTful Web服务将由使用JavaScript编写的客户端使用。通常,客户端会将JSON响应转换为JavaScript对象(通过调用var person = JSON.parse(response))并调用其属性。因此,坚持JavaScript约定使JavaScript代码更具可读性和直观性是一个好主意。
// Don't
person.year_of_birth // violates JavaScript convention
person.YearOfBirth // suggests constructor method
// Do
person.yearOfBirth
使用动词进行操作
有时,对API调用的响应不涉及资源(如计算,转换或转换)。例:
//Reading
GET /translate?from=de_DE&to=en_US&text=Hallo
GET /calculate?para2=23¶2=432
//Trigger an operation that changes the server-side state
POST /restartServer
//no body
POST /banUserFromChannel
{ "user": "123", "channel": "serious-chat-channel" }
在这种情况下,不涉及任何资源。相反,服务器执行操作并将结果返回给客户端。因此,您应该在URL中使用动词而不是名词来清楚地区分操作(RPC样式API)和REST端点(用于建模域的资源)。
创建这些RPC样式的API而不是REST API适合于操作。通常情况下,它比试图将REST风格的操作(如简单,更直观PATCH /server用{"restart": true})。根据经验,REST非常适合与域模型交互,RPC适合于操作。有关更多详细信息,请查看“ 了解RPC与HTTP API的REST ”。
提供分页
一次返回数据库的所有资源几乎绝不是一个好主意。因此,您应该提供分页机制。两种流行的方法是:
- 基于偏移量的分页
- 基于键集的分页又称继续令牌又称光标(推荐)
基于偏移量的分页
一个非常简单的方法是使用的参数offset和limit,这是从数据库中众所周知的。
/employees?offset=30&limit=15 # returns the employees 30 to 45
如果客户端省略了参数,则应使用默认值(如offset=0和limit=100)。永远不要归还所有资源 如果检索更昂贵,您应该减少限制。
/employees # returns the employees 0 to 100
您可以提供获取下一页或上一页的链接。只需构造具有适当偏移量和限制的URL。
GET /employees?offset=20&limit=10
{
"pagination": {
"offset": 20,
"limit": 10,
"total": 3465,
},
"data": [
//...
],
"links": {
"next": "http://www.domain.com/employees?offset=30&limit=10",
"prev": "http://www.domain.com/employees?offset=10&limit=10"
}
}
基于键集的分页(又名Continuation Token,Cursor)
所呈现的基于偏移的分页易于实现,但具有严重的缺点。它们很慢(SQL的OFFSET子句对于大数字变得非常慢)并且不安全(在分页期间发生更改时很容易错过元素)。
这就是使用索引列更好的原因。假设我们的员工有一个索引列data_created,而收集资源/employees?pageSize=100返回按此列排序的最早的100名员工。现在,客户端只需要获取dateCreated最后一个员工的时间戳,并使用查询参数createdSince在此时继续。
GET /employees?pageSize=100
# The client receives the oldest 100 employees sorted by `data_created`
# The last employee of the page has the `dataCreated` field with 1504224000000 (= Sep 1, 2017 12:00:00 AM)
GET /employees?pageSize=100&createdSince=1504224000000
# The client receives the next 100 employees since 1504224000000.
# The last employee of the page was created on 1506816000000. And so on.
这解决了基于偏移的分页的许多缺点,但它仍然不完美,对客户来说不太方便。
- 最好通过向日期添加附加信息(如id)来创建所谓的延续令牌,以提高可靠性和效率。
- 此外,您应该在该令牌的有效负载中提供专用字段,以便客户端不必通过查看元素来弄清楚它。您甚至可以进一步提供
next链接。
所以GET /employees?pageSize=100回报:
{
"pagination": {
"continuationToken": "1504224000000_10",
},
"data": [
// ...
// last element:
{ "id": 10, "dateCreated": 1504224000000 }
],
"links": {
"next": "http://www.domain.com/employees?pageSize=100&continue=1504224000000_10"
}
}
该next链接使API真正具有RESTful,因为客户端只需按照这些链接(HATEOAS)就可以翻阅集合。无需手动构建URL。此外,您可以简单地更改URL结构而不会破坏客户端(evolvability)。
有关更多详细信息,请查看有关Web API分页的专用帖子:
- 使用'Timestamp_Offset_Checksum'继续令牌的Web API分页 - 不再推荐使用建议的方法,但该帖子很好地介绍了整个主题(包括基于偏移的分页)。
- 使用'Timestamp_ID'连续令牌的Web API分页 - 我建议使用此方法。它还包含现有基于键集的分页方法的概述。
查看JSON:API
您至少应该看看JSON:API。它是JSON有效负载的标准格式和HTTP服务的资源(MIME类型:) application/vnd.api+json。我个人并不遵循所有的建议,因为他们中的一些人觉得我有点过于正规化和矫枉过正。在我看来,通常不需要实现灵活性,但它在不提供好处的情况下使实施变得复杂。但这是一个品味问题,遵循标准基本上是一个好主意。我用它作为灵感,挑选那些对我有意义的元素。您可以随意了解JSON:API。
确保API的Evolvability
避免重大变化
理想情况下,REST API(作为每个API)应该是稳定的。基本上,不应该发生破坏性更改(如更改整个有效负载格式或URL方案)。但是,如何在不破坏客户端的情况下继续发展我们的API?
- 进行向后兼容的更改。添加字段没有问题(只要客户端容忍)。
- 复制和弃用。要更改现有字段(重命名或更改结构),可以在旧字段旁边添加新字段,并在文档中弃用旧字段。过了一会儿,你可以删除旧字段。
- 利用超媒体和HATEOAS。只要API客户端使用响应中的链接来浏览API(并且不会手动创建URL),您就可以安全地更改URL而不会破坏客户端。
- 使用新名称创建新资源。如果新业务需求导致全新的域模型和工作流,则可以创建新资源。这通常非常直观,因为域模型无论如何都有一个新名称(从商业名称派生)。示例:租赁服务现在也租用自行车和赛格威。所以
car资源的旧概念/cars不再削减它。引入vehicle了具有新资源的新域模型/vehicles。它与旧/cars资源一起提供。
保持业务逻辑在服务器端
不要让您的服务成为转储数据访问层,它通过直接公开您的数据库模型(低级API)来提供CRUD功能。这产生了高耦合。
- 业务逻辑转移到客户端,通常在客户端和服务器之间复制(只需考虑验证)。我们必须保持同步。
- 通常,客户端耦合到服务器的数据库模型。
我们应该避免创建转储数据访问API,因为它们导致服务器和客户端之间的高度耦合,因为业务工作流在客户端和服务器之间分布。反过来,这又可能使新的业务需求可能需要在客户端和服务器上进行更改并破坏API。因此,API /系统不具备可扩展性。
因此,我们应该构建基于高级/工作流的API而不是低级API。示例:不要为数据库中的订单实体提供简单的CRUD服务。不要求客户端知道要取消订单,客户端必须将订单输入到/order/1具有特定取消有效负载(反映数据库模型)的通用资源中。这导致高耦合(客户端的业务逻辑和领域知识;公开的数据库模型)。相反,提供专用资源/order/1/cancelation并在订单资源的有效负载中添加指向它的链接。客户端可以导航到取消URL并发送定制的取消有效负载。将此有效负载映射到数据库模型的业务逻辑在服务器中完成。此外,服务器可以轻松地更改URL而不会破坏客户端,因为客户端只需跟随链接。此外,如果订单可以取消,则决策逻辑现在在服务器中:如果取消,则服务器可以将订单添加到订单有效负载中的取消资源。因此,客户端只需要检查是否存在取消链接(例如,知道他是否应该取消取消按钮)。因此,我们将域知识从客户端移回服务器。只需触摸服务器即可轻松应用取消条件的更改,这反过来使系统可以进化。无需更改API。
如果您想了解更多有关此主题的内容,我建议使用谈话REST超越显而易见的 -由Oliver Gierke 为不断发展的系统设计API。
考虑API版本控制
然而,您最终可能会遇到上述方法无效的情况,并且您必须提供不同版本的API。版本控制允许您在不破坏客户端的情况下在新版本下发布API的不兼容和重大更改。他们可以继续使用旧版本。客户端可以以自己的速度迁移到新版本。
这个话题在社区中备受争议。您应该考虑到,您可能会在很长一段时间内构建和维护(!)不同版本的API,这很昂贵。
如果您正在构建内部API,那么您很可能了解所有客户。因此,执行重大变更可以再次成为一种选择。但它需要更多的沟通和协调的部署。
不过,以下是两种最流行的版本控制方法:
- 通过URL进行版本控制:
/v1/ - 通过
AcceptHTTP标头进行版本控制:(Accept: application/vnd.myapi.v1+json内容协商)
通过URL进行版本控制
只需将API的版本号放在每个资源的URL中即可。
/v1/employees
优点:
- API开发人员非常简单。
- API客户端非常简单。
- 可以复制和粘贴URL。
缺点:
- 不RESTful。
- 打破网址。客户端必须维护和更新URL。
严格来说,这种方法不是RESTful,因为URL永远不会改变。这可以防止容易进化。将版本放在URL中有一天会破坏API,您的客户必须修复URL。问题是,客户需要花多少精力来更新URL?如果答案是“只是一点点”,那么URL版本可能没问题。
由于其简单性,URL版本控制非常受欢迎,并被 Facebook,Twitter,Google / YouTube,Bing,Dropbox,Tumblr和Disqus等公司广泛使用。
通过AcceptHTTP标头进行版本控制(内容协商)
版本控制的REST更多方式是通过AcceptHTTP请求标头利用内容协商。
GET /employees
Accept: application/vnd.myapi.v2+json
在这种情况下,客户端请求/employees资源的版本2 。因此,我们将不同的API版本视为/employees资源的不同表示,这非常RESTful。v2当客户端仅请求时,您可以将可选和默认设置为最新版本Accept: application/vnd.myapi+json。但公平地告诉他,如果他没有固定版本,他的应用程序将来可能会破坏。
优点:
- 网址保持不变
- 被视为RESTFul
- HATEOAS友好
缺点:
- 稍微难以使用。客户必须注意标题。
- 无法再复制和粘贴网址。
关于版本控制的个人思考
创建新API时,请尝试不使用URL版本控制。特别是内部API可能根本不需要现有资源的真实版本2。您可能会与“避免重大变化”部分中描述的方法相处。如果您最终确实需要现有资源的新版本,您仍然可以进行内容协商并使用Accept标头。但总的来说,最好是构建一个API,首先使破坏性更改的可能性降低(例如,通过构建高级/流程流API并在服务器中保留业务逻辑)。
关于API版本的正确方法以及什么是RESTful以及什么不是什么都有无穷无尽的讨论。人们真的很沮丧。我更乐观务实。对我来说,如果你在版本控制(并使用URL版本控制)时不关心REST理论就完全没问题了,只要它适用于你,你的客户并且你知道即将到来的维护成本。“Protip”:谈论“Web API”或“HTTP API”而不是“REST API”,以诚实地说明与REST的一致性并平息REST狂热者。;-)
进一步阅读
- 我强烈推荐 Phil Sturgeon 编写的“你不会讨厌
的API”这本书
- 我写了一篇关于用Java测试RESTful服务的最佳实践的帖子。
- JSON:API标准
- 对REST的响应是 Phil Sturgeon发布的新SOAP(REST混淆)
- 了解 Phil Sturgeon的RPC Vs REST for HTTP API
via https://phauer.com/2015/restful-api-design-best-practices/