索引一般用于在数据规模大时对查询进行优化的一种机制,对于一般的查询来说,mysql会去遍历整个表,来查询符合要求的结果;如果借助于索引,mysql会将要索引的字段按照一定的算法进行处理,并生成一个类似于书本目录的文件存放在相应的位置,这样在查询时,mysql会先去查找这些"目录",然后根据这些"目录"来快速定位所需记录的位置,这样的查找不用遍历整个记录集,速度自然会很快,对于海量数据尤其如此。
关于如何创建索引,网上有相关的例子,这里不多讲,但是有一个需要注意,在向存在索引的表中插入数据时,因为要维护索引信息,要比不存在索引的表慢一些,因此当数据量大时,可以考虑在插入完数据之后再建立索引。索引分为单列索引和组合索引,对于这两种索引,分别介绍其优化问题。
1、单列索引
单列所有只包含一个字段,一个表可以包含多个单列索引,但是不要把这个和组合索引混淆。利用以下sql创建测试表:
01 |
--创建包含单列索引的index_test_single_a表 |
02 |
CREATE TABLE `index_test_a` ( |
03 |
`id` int(11) NOT NULL AUTO_INCREMENT, |
04 |
`title` char(255) CHARACTER SET utf8 NOT NULL, |
05 |
`content` text CHARACTER SET utf8, |
06 |
`num` int(11) DEFAULT NULL, |
07 |
PRIMARY KEY (`id`), |
08 |
UNIQUE KEY `indexName` (`title`), |
09 |
UNIQUE KEY `numIndex` (`num`) |
10 |
) ENGINE=InnoDB AUTO_INCREMENT=10000 DEFAULT CHARSET=latin1; |
11 |
12 |
--创建不包含单列索引的index_test_single_b表 |
13 |
CREATE TABLE `index_test_b` ( |
14 |
`id` int(11) NOT NULL AUTO_INCREMENT, |
15 |
`title` char(255) CHARACTER SET utf8 NOT NULL, |
16 |
`content` text CHARACTER SET utf8, |
17 |
`num` int(11) DEFAULT NULL, |
18 |
PRIMARY KEY (`id`) |
19 |
) ENGINE=InnoDB AUTO_INCREMENT=10000 DEFAULT CHARSET=latin1; |
其中a表包含title的单列索引,b表的title字段不存在索引,但是两个表都有一个主键id,其实主键也是索引的一种,这个会在后面详细解释。
写程序向这两个表中各导入10000条数据,然后就可以测试了。
1.1、测试查询索引字段所用的时间,代码如下:
01 |
<?php |
02 |
//phpinfo(); |
03 |
ini_set('max_execution_time', 200); |
04 |
$con = mysql_connect("localhost:3306","root","710100"); |
05 |
if (!$con) |
06 |
{ |
07 |
die('Could not connect: ' . mysql_error()); |
08 |
} |
09 |
else{ |
10 |
mysql_select_db("test",$con); |
11 |
|
12 |
|
13 |
$sqlA = "select * from index_test_a where title = 'title_4999';"; |
14 |
|
15 |
|
16 |
|
17 |
$sqlB = "select * from index_test_b where title = 'title_4999';"; |
18 |
|
19 |
$startTimeA = microtime(); |
20 |
|
21 |
|
22 |
|
23 |
$result = mysql_query($sqlA) or die( "Invalid query: " . mysql_error()); |
24 |
|
25 |
$endTimeA = microtime(); |
26 |
|
27 |
echo "A表查询所有记录所用时间:".(($endTimeA-$startTimeA)*1000)."毫秒"; |
28 |
|
29 |
echo "<br>"; |
30 |
|
31 |
$startTimeB = microtime(); |
32 |
|
33 |
$result = mysql_query($sqlB) or die( "Invalid query: " . mysql_error()); |
34 |
|
35 |
$endTimeB = microtime(); |
36 |
|
37 |
echo "B表查询所有记录所用时间:".(($endTimeB-$startTimeB)*1000)."毫秒"; |
38 |
mysql_close($con); |
39 |
} |
40 |
|
41 |
|
42 |
?> |
执行结果如下:
A表查询所有记录所用时间:0.624毫秒
B表查询所有记录所用时间:44.484毫秒
可以看到仅仅10000条记录的查找差别,时间已经相差了几十倍,因此对于经常查询的字段,索引是十分必要的。相应的,如果我们查询没有做索引的字段,那么是没有区别的,将以上的sql语句改为如下所示:
1 |
$sqlA = "select * from index_test_a where content = 'content_4999';"; |
2 |
|
3 |
$sqlB = "select * from index_test_b where content = 'content_4999';"; |
结果如下:
A表查询所有记录所用时间:23.848毫秒
B表查询所有记录所用时间:24.155毫秒
1.2、测试like查询
在我们项目中,如果数据量大,则不推荐like查询,因为其查询效率比较低,但是对于索引字段来说,like能命中吗?
可以将sql语句改成如下所示:
1 |
$sqlA = "select * from index_test_a where title like '4999%'"; |
2 |
$sqlB = "select * from index_test_b where title like '4999%'"; |
测试结果如下:
A表查询所有记录所用时间:0.488毫秒
B表查询所有记录所用时间:25.281毫秒
可以看到对于模糊查询来说,如果是前缀匹配,则会命中索引,但是如果我们将sql改为后缀匹配或者任意匹配,那么二者所消耗的查询时间是一致的:
1 |
$sqlA = "select * from index_test_a where title like '%4999'"; |
2 |
$sqlB = "select * from index_test_b where title like '%4999'"; |
1 |
$sqlA = "select * from index_test_a where title like '%4999'"; |
2 |
$sqlB = "select * from index_test_b where title like '%4999'"; |
A表查询所有记录所用时间:44.742毫秒
B表查询所有记录所用时间:45.752毫秒
即二者都没有命中索引。
1.3、测试or语句,将sql改为如下所示:
1 |
$sqlA= "select * from index_test_a where content='content_4999' or title='title_4999';"; |
2 |
3 |
$sqlB= "select * from index_test_b where content='content_4999' or title='title_4999';"; |
测试结果如下:
A表查询所有记录所用时间:49.904毫秒
B表查询所有记录所用时间:50.131毫秒
继续将sql改为如下:
1 |
$sqlA = "select * from index_test_a where id=4999 or title='title_4999';"; |
2 |
3 |
$sqlB = "select * from index_test_b where id=4999 or title='title_4999';"; |
测试结果如下:
A表查询所有记录所用时间:0.86毫秒
B表查询所有记录所用时间:47.318毫秒
从上面的结果可以看到,当or中有一个字段没有索引的时候,那么将不会命中索引;反之,如果or运算的所有字段均做了索引,那么是可以命中的。
1.4、测试in,将sql语句继续改为如下所示:
1 |
$sqlA= "select title from index_test_a where title in ('title_4999','title_5000');"; |
2 |
$sqlB= "select title from index_test_b where title in ('title_4999','title_5000');"; |
测试结果为:
A表查询所有记录所用时间:0.817毫秒
B表查询所有记录所用时间:24.234毫秒
可见对于索引字段,in也是可以命中索引的。
1.5、测试<,>,between等,将sql改为如下所示:
1 |
$sqlA = "select title from index_test_a where num < 999;"; |
2 |
$sqlB = "select title from index_test_b where num < 999;"; |
测试结果如下:
A表查询所有记录所用时间:11.469毫秒
B表查询所有记录所用时间:21.728毫秒
可见二者差别不是很大,因此是没有命中索引的。
1.6、对于mysql函数,索引的命中,将sql改为如下所示:
1 |
$sqlA = "select num from index_test_a where char(num) in ('999','9999');"; |
2 |
$sqlB = "select num from index_test_b where char(num) in ('999','9999');"; |
得到的结果如下所示:
A表查询所有记录所用时间:11.322毫秒
B表查询所有记录所用时间:12.429毫秒
所以如果在条件中使用函数,那么索引将会失效。
2、组合索引
组合索引包括对多个列的索引,而不是多个单列索引的组合,将表a中的所以改成(title,num)的组合索引,进行以下测试:
2.1、or测试
将sql语句改成如下所示:
1 |
$sqlA = "select * from index_test_a where num=4999 or title='title_4999';"; |
2 |
$sqlB = "select * from index_test_b where num=4999 or title='title_4999';"; |
结果如下所示:
A表查询所有记录所用时间:52.535毫秒
B表查询所有记录所用时间:53.031毫秒
这时索引没有命中,索引组合索引的or运算和两个单列索引的or运算是不同的,前者失效而后者依然有效。
2.2、and测试
将sql语句改成如下所示:
1 |
$sqlA = "select * from index_test_a where num=4999 and title='title_4999';"; |
2 |
$sqlB = "select * from index_test_b where num=4999 and title='title_4999';"; |
结果如下所示:
A表查询所有记录所用时间:0.666毫秒
B表查询所有记录所用时间:43.042毫秒
继续改为如下所示:
1 |
$sqlA = "select * from index_test_a where num=4999 ;"; |
2 |
$sqlB = "select * from index_test_b where num=4999 ;"; |
得到的结果为:
A表查询所有记录所用时间:39.398毫秒
B表查询所有记录所用时间:41.057毫秒
而改成如下sql:
1 |
$sqlA = "select * from index_test_a where title='title_'4999 ;"; |
2 |
$sqlB = "select * from index_test_b where title='title_4999' ;"; |
得到的结果则为:
A表查询所有记录所用时间:0.753毫秒
B表查询所有记录所用时间:48.248毫秒
由以上三组结果可以看出,组合索引是最左前缀匹配的,即条件中要包含第一个索引列,才会命中索引。
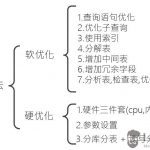
3、 索引的优缺点
利用索引可以大大加快我们的搜索,但是维护索引需要额外的开销,尤其是当索引较多的时候,大量的数据会很容易带来索引量的膨胀,因此对于频繁要用到的查询,我们才需要做索引,这样才能以最小的代价获得最大的性能提升。