If your application is running slow or making a lot of database queries, follow the below performance optimization tips to improve your application loading time.
1. Retrieving Large Datasets
This tip mainly focuses on improving the memory usage of your application when dealing with large datasets.
If your application needs to process a large set of records, instead of retrieving all at once, you can retrieve a
a subset of results and process them in groups.
To retrieve many results from a table called posts, we would usually do like below.
The above examples will retrieve all the records from the posts table and process them. What if this table has 1 million rows? We will quickly run out of memory.
To avoid issues when dealing with large datasets, we can retrieve a subset of results and process them as below.
Option 1: Using chunk
The above example retrieves 100 records from the posts table, processes them, retrieves another 100 records, and processes them. This iteration will continue until all the records are processed.
This approach will create more database queries but be more memory efficient. Usually, the processing of large datasets should
be doe in the background. So it is ok to make more queries when running in the background to avoid running out of memory when processing large datasets.
Option 2: Using cursor
The above example will make a single database query, retrieve all the records from the table, and hydrate Eloquent models one by one. This approach will make only one database query to retrieve all the posts. But uses php generator to optimize the memory usage.
when can you use this?
Though this greatly optimizes the memory usage on the application level, Since we are retrieving all the entries from a table,
the memory usage on the database instance will still be higher.
It is better to use a cursor If your web app running your application has less memory, and the database instance has more memory. However, if your database instance does not have enough memory, it is better to stick to chunks.
option 3: Using chunkById
The major difference between chunk and chunkById is that chunk retrieves based on offset and limit. Whereas
chunkById retrieves database results based on an id field. This id field usually be an integer field, and in most cases it would be an auto-incrementing field.
The queries made by chunk and chunkById were as follows.
chunk
chunkById
Generally, using a limit with offset is slower, and we should try to avoid using it. This article explains in detail the problem with using offset.
As chunkById is using the id field which is an integer, and the query is using a where clause, the query will be much faster.
When can you use chunkById?
- If your database table has a
primary key columncolumn, which is an auto-incrementing field.
2. Select only the columns you need
Usually to retrieve results from a database table, we would do the following.
The above code will result in a query as below
As you can see, the query is doing a select *. This means it is retrieving all the columns from the database table.
This is fine if we really need all the columns from the table.
Instead, if we need only specific columns(id, title), we can retrieve only those columns as below.
The above code will result in a query as below
3. Use pluck when you need exactly one or two columns from the database
This tip focuses more on the time spent after the results are retrieved from the database. This does not affect the actual query time.
As I mentioned above, to retrieve specific columns, we would do
When the above code is executed, it does the following behind the scenes.
- Executes
select title, slug from postsquery on the database - Creates a new
Postmodel object for each row it retrieved(For query builder, it creates a PHP standard object) - Creates a new collection with the
Postmodels - Returns the collection
Now, to access the results, we would do
The above approach has an additional overhead of hydrating Post model for each and every row and creating a collection for these objects. This would be best if you really need the Post model instance instead of the data.
But if all that you need is those two values, you can do the following.
When the above code is executed, it does the following behind the scenes.
- Executes
select title, slug from postsquery on the database - Creates an array with
titleasarray valueandslugasarray key. - Returns the array(array format:
[ slug => title, slug => title ])
Now, to access the results, we would do
If you want to retrieve only one column, you can do
The above approach eliminates the creation of Post objects for every row. Thus reducing the memory usage and
time spent on processing the query results.
I would recommend using the above approach on new code only. I personally feel going back and refactoring your code
to follow the above tip is not worthy of the time spent on it. Refactor existing code only if your code is processing large
datasets or if you have free time to spare.
4. Count rows using a query instead of a collection
To count the total no of rows in a table, we would normally do
This will generate the following query
The above approach will retrieve all the rows from the table, load them into a collection object, and counts the results. This works fine when there are less rows in the database table. But we will quickly run out of memory as the
table grows.
Instead of the above approach, we can directly count the total no of rows on the database itself.
This will generate the following query
Counting rows in sql is a slow process and performs poorly when the database table has so many rows. It is better to avoid counting of rows as much as possible.
5. Avoid N+1 queries by eager loading relationship
You might have heard of this tip a million times. So I will keep it as short and simple as possible. Let's assume you have the following scenario
The above code is retrieving all the posts and displaying the post title and its author on the webpage, and it assumes you have an author relationship on your post model.
Executing the above code will result in running following queries.
As you can see, we have one query to retrieve posts, and 5 queries to retrieve authors of the posts(Since we assumed we have 5 posts.) So for every post it retrieved, it is making one separate query to retrieve its author.
So if there are N number of posts, it will make N+1 queries( 1 query to retrieve posts and N queries to retrieve the author for each post). This is commonly known as N+1 query problem.
To avoid this, eager load the author's relationship on posts as below.
Executing the above code will result in running the following queries.
6. Eager load nested relationship
From the above example, consider the author belongs to a team, and you wish to display the team name as well. So in the
blade file you would do as below.
Now doing the below
Will result in following queries
As you can see, even though we are eager loading authors relationship, it is still making more queries. Because we
are not eager loading the team relationship on authors.
We can fix this by doing the following.
Executing the above code will result in running following queries.
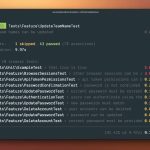
By eager loading the nested relationship, we reduce the total number of queries from 11 to 3.
7. Do not load belongsTo relationship if you just need its id
Imagine you have two tables posts and authors. Posts table has a column author_id which represents a belongsTo
relationship on the authors table.
To get the author id of a post, we would normally do
This would result in two queries being executed.
Instead, you can directly get the author id by doing the following.
When can I use the above approach?
You can use the above approach when you are confident that a row always exists in authors table if it is referenced
in posts table.
8. Avoid unnecessary queries
Oftentimes, we make database queries that are not necessary. Consider the below example.
The above code is retrieving rows from two different tables(ex: posts, private_posts) and passing them to view.
The view file looks as below.
As you can see above, $private_posts is visible to only a user who is an admin. Rest all the users cannot see
these posts.
The problem here is, when we are doing
We are making two queries. One to get the records from posts table and another to get the records
from private_posts table.
Records from private_posts table are visible only to the admin user. But we are still making the query to retrieve
these records for all the users even though they are not visible.
We can modify our logic to below to avoid this extra query.
By changing our logic to the above, we are making two queries for the admin user and one query for all other users.
9. Merge similar queries
We sometimes need to make queries to retrieve different kinds of rows from the same table.
The above code is retrieving rows with a different status from the same table. The code will result in making
following queries.
As you can see, it is making three different queries to the same table to retrieve the records. We can refactor this code
to make only one database query.
The above code is making one query to retrieve all the posts which has any of the specified status and creating separate collections for each status by filtering the returned posts by their status. So we will still have
three different variables with their status and will be making only one query.
10. Add index to frequently queried columns
If you are making queries by adding a where condition on a string based column, it is better to add an index to
the column. Queries are much faster when querying rows with an index column.
In the above example, we are querying records by adding a where condition to the status column. We can improve the
performance of the query by adding the following database migration.
11. Use simplePaginate instead of Paginate
When paginating results, we would usually do
This will make two queries, the first to retrieve the paginated results and a second to count the total no of rows in the table. Counting rows in a table is a slow operation and will negatively affect the query performance.
So why does laravel count the total no of rows?
To generate pagination links, Laravel counts the total no of rows. So, when the pagination links are generated, you know before-hand, how many pages will be there, and what is the past page number. So you can navigate to what ever the page you want easily.
On the other hand, doing simplePaginate will not count the total no of rows and the query will be much faster than the paginate approach. But you will lose the ability to know the last page number and able to jump to different pages.
If your database table has so many rows, it is better to avoid paginate and do simplePaginate instead.
When to use paginate vs simple paginate?
Look at the below comparison table and determine if paginate or simple paginate is right for you
| paginate / simplePaginate | |
|---|---|
| database table has only few rows and does not grow large | paginate / simplePaginate |
| database table has so many rows and grows quickly | simplePaginate |
| it is mandatory to provide the user option to jump to specific pages | paginate |
| it is mandatory to show the user total no of results | paginate |
| not actively using pagination links | simplePaginate |
| UI/UX does not affect from switching numbered pagination links to next / previous pagination links | simplePaginate |
| Using "load more" button or "infinite scrolling" for pagination | simplePaginate |
12. Avoid using leading wildcards(LIKE keyword)
When trying to query results which match a specific pattern, we would usually go with
The above query will result in a full table scan. If We know the keyword occurs at the beginning of the column value,
We can query the results as below.
13. avoid using SQL functions in where clause
It is always better to avoid SQL functions in where clause as they result in full table scan. Let's look at the below
example. To query results based on the certain date, we would usually do
This will result in a query similar to below
The above query will result in a full table scan, because the where condition isn't applied until the date function
is evaluated.
We can refactor this to avoid the date sql function as below
14. avoid adding too many columns to a table
It is better to limit the total no of columns in a table. Relational databases like mysql, can be leveraged to split the tables with so many columns into multiple tables. They can be joined together by using their primary and
foreign keys.
Adding too many columns to a table will increase the individual record length and will slow down the table scan. When you are doing a select * query, you will end up retrieving a bunch of columns which you really do not need.
15. separate columns with text data type into their own table
This tip is from personal experience and is not a standard way of architecting your database tables. I recommend to
follow this tip only if your table has too many records or will grow rapidly.
If a table has columns which stores large amounts of data(ex: columns with a datatype of TEXT), it is better to separate
them into their own table or into a table which will be less frequently asked.
When the table has columns with large amounts of data in it, the size of an individual record grows really high. I
personally observed it affected the query time on one of our projects.
Consider a case where you have a table called posts with a column of content which stores the blog post content.
The content for blog post will be really huge and often times, you need this data only if a person is viewing this
particular blog post.
So separating this column from the posts table will drastically improve the query performance when there are too many posts.
16. Better way to retrieve latest rows from a table
When we want to retrieve latest rows from a table, we would often do
The above approach will produce the following sql query.
The query is basically ordering the rows in descending order based on the created_at column. Since created_at column is
a string based column, it is often slower to order the results this way.
If your database table has an auto incrementing primary key id, then in most cases, the latest row will always have the
highest id. Since id field is an integer field and also a primary key, it is much faster to order the results based on
this key. So the better way to retrieve latest rows is as below.
17. optimize MySQL inserts
We so far looked into optimizing select queries for retrieving results from a database. Most cases we only need to optimize the read queries. But sometimes we find a need to optimize insert and update queries. I found an interesting article on optimizing mysql inserts
which will helps in optimizling slow inserts and updates.
18. Inspect and optimize queries
There is no one universal solution when optimizing queries in laravel. Only you know what your application is doing,
how many queries it is making, how many of them are actually in use. So inspecting the queries made by your application
will help you determine and reduce the total number of queries made.
There are certain tools which helps you in inspecting the queries made on each and every page.
Note: It is recommended not to run any of these tools on your production environment. Running these on your production
apps will degrade your application performance and when compromised, unauthorized users will get access to sensitive information.
- Laravel Debugbar - Laravel debugbar has a tab called
database
which will display all the queries executed when you visit a page. Visit all the pages in your application and look at the queries executed on each page. - Clockwork - Clockwork is same as laravel debugbar. But instead of injecting a toolbar into your website, it will display the debug information in
developer tools windowor as a
standalone UI by visitingyourappurl/clockwork. - Laravel Telescope - Laravel telescope is a wonderful debug companion while developing laravel applications locally. Once Telescope is installed, you can access the dashboard by visiting
yourappurl/telescope. In the telescope dashboard, head over toqueriestab, and it will display all the queries being executed by your application.