键入网址到网页显示,期间发生了什么?
- 浏览器解析请求的 URL
http: + // + domain.com + / + index.html 协议 + // + 服务器地址 + / + 文件路径 - 生成 HTTP 请求报文
GET / HTTP/1.1 Accept: */* - DNS 查询
浏览器先查有没这个域名的缓存,
如果没有就去问操作系统层面有没这个域名的缓存,
如果没有就去操作系统的 hosts 文件查询有没配置.
如果没有就去本地 DNS 服务器 (我电脑默认自动获取)
![HTTP[快问快答系列]](https://cdn.learnku.com/uploads/images/202303/04/43677/71IkT8X1FR.png!large)
如果本地 DNS 服务器也没有域名的缓存就会去问根服务器拿 IP
根服务器不负责解析域名,只返回顶级域名的服务器地址,比如.com 域名的服务器地址
本地 DNS 服务器去问.com 域名服务器地址拿 IP
.com 域名服务器返回负责这个二级域名的 DNS 服务器地址
本地 DNS 服务器去问二级域名 DNS 服务器拿 IP
成功拿到 IP 并在本地 DNS 服务器,浏览器和操作系统都缓存起来 - 协议栈
浏览器通过 DNS 查询到的 IP 和解析 URL 查询到的端口用操作系统提供的 socket 库连接服务器,通过三次握手建立 tcp 连接,客户端和服务器双方生成通信 socket 文件$socket = socket_create(AF_INET, SOCK_STREAM, SOL_TCP); socket_connect($socket, 'ip', '端口'); - TCP 层 可靠传输
建立好 tcp 连接之后,HTTP 报文加上 TCP 报文头部,如果报文长度超过了 MSS 长度就会拆解分包发送 - IP 层 远程定位
TCP 报文头部加上 IP 报文头部 - MAC 层 两点传输
IP 报文头部加上 MAC 报文头部 - 网卡把报文转换成电信号,发送到交换机,再发送到路由器,路由器转发上层路由器一直到达服务器
- 服务器按同样的步骤组装返回报文,原路返回逐层去掉头部最终返回到浏览器的 http 报文长这个样子
HTTP/1.1 200 OK Date: Mon, 23 May 2005 22:38:34 GMT Content-Type: text/html; charset=UTF-8 Content-Length: 155 Connection: close <html> <head> <title>An Example Page</title> </head> <body> <p>Hello World, this is a very simple HTML document.</p> </body> </html>
GET 与 POST 的区别
- GET
浏览器对 GET 请求的 URL 会有长度限制,对 GET 请求可以缓存,也可以保存书签,历史记录,只支持 url 编码 - POST
POST 请求的数据在浏览器 URL 上不可见,支持 url 编码,multipart/form-data 等编码, - 总结
以上是 GET 和 POST 在浏览器上的区别,在 HTTP 协议上,并没有本质的区别,一般 GET 用来获取数据,POST 用来提交数据,GET 也可以像 POST 一样传 body, 只不过 RFC 规范不建议你这么做
HTTP 缓存有哪些实现方式?
- 强制缓存
Cache-Control 是 HTTP/1.1 的标准,而 Expires 则是 HTTP/1.0 的标准,Cache-Control 的优先级高于 Expires。通常使用 Cache-Control, 比较灵活。Cache-Control: public:响应可以被客户端和代理服务器缓存。 private:响应只能被客户端缓存,不能被代理服务器缓存。 no-cache:客户端和代理服务器都不能缓存响应,需要重新获取。 no-store:响应不能被缓存或存储。 max-age:响应的最大有效时间,单位为秒。 s-maxage:覆盖 max-age,仅适用于共享缓存,例如代理服务器。Expires:过期时间:响应的绝对过期时间,使用 GMT 格式表示。 - 协商缓存
协商缓存需要配合强制缓存中 Cache-Control 来使用,只有在未能命中强制缓存的时候,才能发起带有协商缓存字段的请求。服务器根据一下两种方式判断文件没有修改则返回 304 Not Modified,不会返回资源1.请求头If-Modified-Since和响应头Last-Modified 2.请求头If-None-Match与响应头部ETag
HTTP 常见的状态码有哪些?
- 1xx 类状态码属于提示信息,是协议处理中的一种中间状态,实际用到的比较少。
- 200 : 表示一切正常。
- 204 : 与 200 OK 基本相同,但响应头没有 body 数据
- 206 : 应用于 HTTP 分块下载或断点续传
- 301 : 永久重定向
- 302 : 临时重定向,说明请求的资源还在
- 304 : 表示资源未修改,重定向已存在的缓冲文件
- 400 : 客户端请求的报文有错误
- 403 : 服务器禁止访问这个资源
- 404 : 资源在服务器上不存在
- 500 : 服务器发生了错误
- 501 : 客户端请求的功能服务端还没法开发好
- 502 : phpfpm 发生错误时,nginx 返回的状态码
- 503 : 服务器当前很忙,暂时无法响应客户端
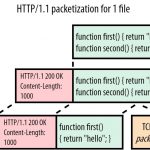
HTTP/1.1 相比 HTTP/1.0 提高了什么性能?
- 使用长连接的方式改善了 HTTP/1.0 短连接造成的性能开销。
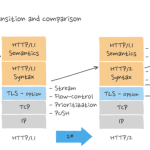
HTTP/2 做了什么优化?#
HTTP/2 协议是基于 HTTPS 的,所以 HTTP/2 的安全性也是有保障的。
- 头部压缩
HTTP/2 会压缩头(Header)如果你同时发出多个请求,他们的头是一样的或是相似的,那么,协议会帮你消除重复的部分。
这就是所谓的HPACK算法:在客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就提高速度了。 - 二进制格式
全面采用了二进制格式,头信息和数据体都是二进制,并且统称为帧,收到报文后,无需再将明文的报文转成二进制,而是直接解析二进制报文,这增加了数据传输的效率 - 并发传输
引出了 Stream 概念,多个 Stream 复用在一条 TCP 连接。 - 服务器推送
主动向客户端发送消息。
HTTP/2 有什么缺陷?#
HTTP/2 通过 Stream 的并发能力,解决了 HTTP/1 队头阻塞的问题,看似很完美了,但是 HTTP/2 还是存在 “队头阻塞” 的问题,只不过问题不是在 HTTP 这一层面,而是在 TCP 这一层。
HTTP/2 是基于 TCP 协议来传输数据的,TCP 是字节流协议,TCP 层必须保证收到的字节数据是完整且连续的,这样内核才会将缓冲区里的数据返回给 HTTP 应用,那么当「前 1 个字节数据」没有到达时,后收到的字节数据只能存放在内核缓冲区里,只有等到这 1 个字节数据到达时,HTTP/2 应用层才能从内核中拿到数据,这就是 HTTP/2 队头阻塞问题。
所以,一旦发生了丢包现象,就会触发 TCP 的重传机制,这样在一个 TCP 连接中的所有的 HTTP 请求都必须等待这个丢了的包被重传回来。
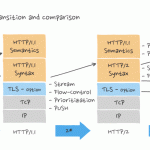
HTTP/3 做了哪些优化?
- 无队头阻塞
- 使用 QUIC 协议 底层是 UDP
- 连接迁移 对移动设备非常友好
HTTPS 是如何建立连接的?其间交互了什么?#
首先三次握手建立 TCP 连接,成功之后马上建立 SSL/TCS 连接
SSL/TLS 协议基本流程:
- 客户端向服务器索要并验证服务器的公钥。
- 双方协商生产「会话秘钥」。
- 双方采用「会话秘钥」进行加密通信。
SSL/TLS 协议详细流程:
- ClientHello
首先,由客户端向服务器发起 ClientHello 请求。
在这一步,客户端主要向服务器发送以下信息:
(1)客户端支持的 TLS 协议版本,如 TLS 1.2 版本。
(2)客户端生产的随机数(Client Random),后面用于生成「会话秘钥」条件之一。
(3)客户端支持的密码套件列表,如 RSA 加密算法。 - SeverHello
服务器收到客户端请求后,向客户端发出响应,也就是SeverHello。服务器回应的内容有如下内容:
(1)确认 TLS 协议版本,如果浏览器不支持,则关闭加密通信。
(2)服务器生产的随机数(Server Random),也是后面用于生产「会话秘钥」条件之一。
(3)确认的密码套件列表,如 RSA 加密算法。
(4)服务器的数字证书。 - 客户端回应
客户端收到服务器的回应之后,首先通过浏览器或者操作系统中的 CA 公钥,确认服务器的数字证书的真实性。
如果证书没有问题,客户端会从数字证书中取出服务器的公钥,然后使用它加密报文,向服务器发送如下信息:
(1)一个随机数(pre-master key)。该随机数会被服务器公钥加密。
(2)加密通信算法改变通知,表示随后的信息都将用「会话秘钥」加密通信。
(3)客户端握手结束通知,表示客户端的握手阶段已经结束。
服务器和客户端有了这三个随机数(Client Random、Server Random、pre-master key),接着就用双方协商的加密算法,各自生成本次通信的「会话秘钥」。 - 服务器的最后回应
服务器收到客户端的第三个随机数(pre-master key)之后,通过协商的加密算法,计算出本次通信的「会话秘钥」。
然后,向客户端发送最后的信息:
(1)加密通信算法改变通知,表示随后的信息都将用「会话秘钥」加密通信。
(2)服务器握手结束通知,表示服务器的握手阶段已经结束。
至此,整个 TLS 的握手阶段全部结束。接下来,客户端与服务器进入加密通信,就完全是使用普通的 HTTP 协议,只不过用「会话秘钥」进行对称加密内容。
CA 证书签发过程#
- 首先 CA 会把持有者的公钥、用途、颁发者、有效时间等信息打成一个包,然后对这些信息进行 Hash 计算,得到一个 Hash 值;
- 然后 CA 会使用自己的私钥将该 Hash 值加密,生成 Certificate Signature,也就是 CA 对证书做了签名;
- 最后将 Certificate Signature 添加在文件证书上,形成数字证书;
吐槽一下动动手的事情竟然要卖几千块一年
客户端校验 CA 证书的流程是怎样的?
- 首先客户端会使用同样的 Hash 算法获取该证书的 Hash 值 H1;
- 通常浏览器和操作系统中集成了 CA 的公钥信息,浏览器收到证书后可以使用 CA 的公钥解密 Certificate Signature 内容,得到一个 Hash 值 H2 ;
- 最后比较 H1 和 H2,如果值相同,则为可信赖的证书,否则则认为证书不可信。
HTTPS 一定安全可靠吗?#
不一定,如果客户端通过浏览器向服务端发起 HTTPS 请求时,被「假基站」转发到了一个中间人服务器,形成中间商赚差价,简称中间人攻击
- 客户端向中间人服务器发起 https 请求
- 中间人服务器返回自己的 CA 证书
- 成功建立连接
- 中间人成功解密获取客户端发送的加密报文
- 中间人服务器再跟目标服务器建立 https 连接
- 转发客户端的数据给目标服务器
- 转发目标服务器的报文给客户端
这种攻击的前提是你信任了中间人服务器的 CA 证书,或者被木马植入了中间人的 CA 证书,https 协议本身是没漏洞的,中间人攻击本质是利用了客户端的漏洞,不关 https 的事情
为什么抓包工具能截取 HTTPS 数据?#
工作原理跟中间人攻击一致
如何避免被中间人抓取数据?#
通过 HTTPS 双向认证来避免这种问题。这样客户端也要有自己的 CA 证书,双方交换证书确认身份再建立连接
本作品采用《CC 协议》,转载必须注明作者和本文链接
遇强则强,太强另说

![一文串联 HTTP / [0.9 | 1.0 | 1.1 | 2 | 3]](https://blog.p2hp.com/wp-content/plugins/wordpress-23-related-posts-plugin/static/thumbs/14.jpg)

HTTP[快问快答系列]