本文实例为大家分享了js实现拖拽与碰撞检测的具体代码,供大家参考,具体内容如下

拖拽
原理分析
对于拖拽一个div盒子,首先我们需要将鼠标移动到盒子上,然后按住鼠标左键,移动鼠标到目标位置,再松开鼠标,对于这一过程的分析,
显然需要三个鼠标事件:
- 按住鼠标:onmousedown
- 移动鼠标:onmousemove
- 松开鼠标:onmouseup
实现步骤
1、**鼠标按下时:**我们获取鼠标当前所在的位置距离页面左边界与上边界的距离,分别减去盒子距离页面左边界与上边界的值,这样我们
就得到了鼠标距离盒子左边界与上边界的值;
2、**鼠标移动时:**我们重新获取此时鼠标距离页面左边界与上边界的值,再用它们减去步骤一中得到的鼠标距离盒子左边界与上边界的
值,将得到的值重新赋给盒子,这样盒子就能与鼠标保持相对静止,在页面上移动;
3、**松开鼠标时:**将鼠标移动事件清除。
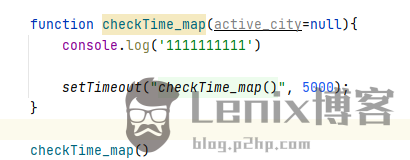
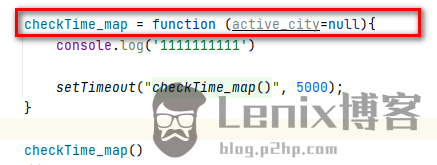
实现代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20 |
近期评论